こんにちは。ファンと共に時代を進める、Web3スタートアップ Gaudiy で、ブロックチェーン周りの開発をリードしているDoi(@taro_engineer)です。
「2023年は、Web3 のマスアダプションに向けて躍進する年だ」と昨年の後半くらいから言われていましたが、実際に、技術的にも法規制的にも進展があった一年だったと思います。
GaudiyもWeb3のマスアダプションに対して、長らく課題意識を持ってきましたが、今年は事業としても大きな転換を迎える年となりました。(このあたりの Gaudiy の事業背景や変遷は、ぜひ以下の記事をご覧いただければと思います。)
中でも、大きな進展として注目すべきポイントの一つが、ERC-4337 の Audit です。Gaudiy としても Account Abstraction、特に ERC-4337 には注視していたので、大きなニュースでした。
ERC-4337 は Draft ですが、OpenZeppelin による ERC-4337 Core チームのコントラクト Audit のニュースを見たときに、今後 ERC-4337 を開発していく流れを止めることはできないと確信しました。
The rumors are true... ERC-4337 has been deployed on mainnet 🚀
— erc4337 (@erc4337) 2023年3月2日
🔍 Security audit by @OpenZeppelin
🛠️ Bundlers and paymasters by @stackup_fi, @AlchemyPlatform, @biconomy , @etherspot, @candidewallet, @blocknative & more
🏗️ $300K in grants by @ethereum pic.twitter.com/WOjMvaZe6M
これを受けて、実際にGaudiy のプロダクトに適用するにはどうするか?を考え、実装してみたため、今回は ERC-4337を実装する上で感じた課題や今後の展望について書いてみたいと思います。
1. Web3のマスアダプションに向けた課題
Web3 ひいてはブロックチェーンの世界に、一般ユーザーも参加してもらうには、まず大きな課題が2つあります。
- ウォレット(EOA)という新しい概念のアカウントを管理しないといけない
- ガス代という手数料の存在
それぞれの課題に対して単独での解決策はあり、それらを組み合わせることで、一般的なアプリに慣れているユーザーにもブロックチェーンの世界に足を踏み入れてもらうことはできました。
一方で、完全に自由な活動をユーザーが実現するのは難しく、その解決にはスマートコントラクトのアップデートが必要など、一部のユースケースにしか対応できないという難点もありました。
すべてのオンチェーン活動に対して自由に活動できて、ユーザーが余計な学習を必要としない状態にするには、まだ一歩足らない部分があったように感じます。
2. ERC-4337 とはなにか?
上記の問題を解決するために、Account Abstraction という技術でウォレットを作ることが考えられます。これは、ブロックチェーン上のスマートコントラクトをウォレットとし、EOA と同じ振る舞いができるように、署名とガス代の抽象化を実装するシステム全体のことを指します。
そして ERC-4337 は、Ethereum 系ネットワークのアプリケーションレイヤーで Account Abstraction を実装するための標準規格にあたり、Account Abstraction の最前線といっても過言ではない提案にあたります。
Ethereum 系ネットワークのコントラクト開発で標準規格化していくであろう提案ということは、つまり、どの開発者・プロバイダーでも周辺のエコシステムを利用すれば拡張できる。例えば、 Bundler・Paymaster を切り替えて利用できたりすることが、利点として考えられます。
また、トランザクションの署名に ECDSA 以外を利用するなど、署名の抽象化も実現できるため、今後の課題になるであろう暗号の強度や、署名検証の効率化などに対しても対策ができるのが特徴です。
これ以上の詳しい内容は、他の記事などを探せば出てくるので、ここでは深く言及しないようにします。
ERC-4337 を実装するにあたり、関連記事をひとつだけ紹介すると、個人的には Alchemy が出しているブログを読めば、ERC-4337 がだいたいわかると思っています。
Account Abstraction を実装していく中で発生する課題を解決していき、最終的にERC-4337 の複雑さに行き着くまでのプロセスを紹介してくれているので、各登場人物が何を目的として存在するのか?がよくわかります。
このブログなどを参考に、実際の動きを確かめながら実装を進めました。
3. ERC-4337 実装のポイントと展望
ではここから、実際の ERC-4337 の実装について書いていきます。この章では、大きく分けて以下3つのポイントをご紹介したいと思います。
- アップグレードについて
- ウォレットのリカバリーについて
- 転売の防止について
まず、ERC-4337 を Production レベルで実装する際に、必ず考慮する必要がでてくる “アップグレード” と “ウォレットのリカバリー” 。そして、Gaudiyの事業特性上考える必要があった “転売の防止” について言及していきます。
前提としてGaudiyのウォレット構成は、以下のようなイメージ(概念図)となります。
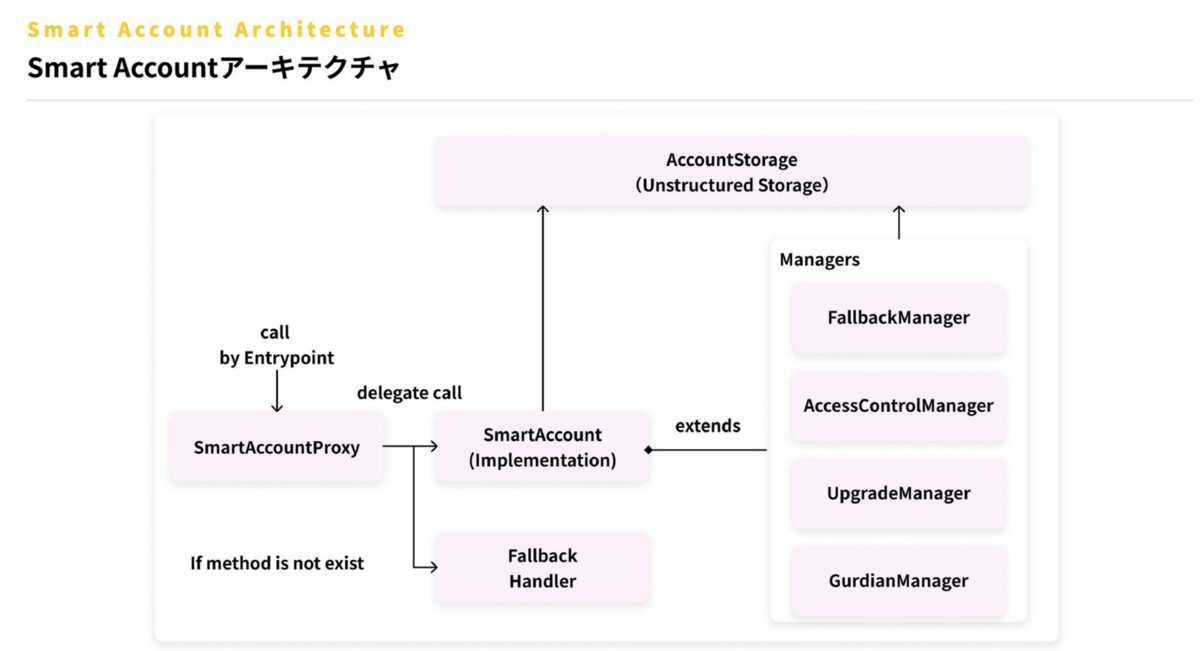
簡単に説明すると、コントラクトの Storage に関わるデータは AccountStorage で定義して、ロジックの変更によって collision を引き起こす可能性を減らしています。各ロジックは Manager として定義し、最低限必要な機能を備えました。
SmartAccount というコントラクトが各ロジックを束ねており、これをシングルトンとしてネットワークにデプロイします。
各ユーザーごとのアカウントとして Proxy をデプロイし、ウォレットのアップグレードが必要な場合は、ユーザーからトランザクションを発行してもらい、事前にデプロイした新しいシングルトンコントラクトに向き先を変えてもらいます。
それでは各セクションについて、記載していきたいと思います。
3-1. アップグレードについて
1つめは、アップグレードです。スマートコントラクトの実装において、最も神経を使う部分の1つが Upgradeable なコントラクトの実装だと思っています。
今までの開発であれば、OpenZeppelin のコントラクトでも一般的に提供されている ERC-1967 を利用した Proxy Pattern が、一番メジャーで使用されている選択肢かなと思います。
スマートコントラクトウォレットに関しては、この通例とされる Upgrade とは少し違うアプローチを考えなければいけません。
3-1-1. モジュラーコントラクト
まず ERC-4337 は EIP ではまだ Draft であり、今後仕様が変わる可能性が大きいです。さらに、ユーザーのアカウントという性質上、セキュリティの脆弱性に対する対応や、今後ユーザーが新機能を追加したい/逆に削除したいと感じる可能性なども、NFTなどのコントラクトと比べると高いと考えられます。
そのため、コントラクトを拡張していく考え方をもつ従来の Proxy Pattern では、スケールするウォレットを提供することは難しいと感じました。
この点から、ウォレットの実装でよく見られるのは “モジュール” という概念を用いた実装です。
ざっくりしたイメージで言うと、ERC-2535 の Diamond Proxy の考え方をベースとし、各ロジックを組み替えたり、付け替えたりできるようにモジュール化する手法です。Account Abstraction のパイオニアと呼べる各プロジェクト、例えば Safe や Argent などには、この “モジュール” という要素が組み込まれています。
ERC-4337 の文脈でいくと、ERC-6900 の提案がより標準化に向けたモジューラブルなスマートコントラクトウォレットの実装につながると考えています。これもまだ Draft なので、今も Spec が変わりつつありますが、基本的な考え方はすでに長年 Account Abstraction に取り組んでいるプロジェクトでも利用されていたりします。
また、Alchemy のエンジニアが提案者なので、今後 Alchemy という大きなプラットフォーマーが ERC-6900 の標準化に向けて大きく推進させていったり、Account Abstraction の開発市場を取りに行くような動きをする可能性があると感じています。
3-1-2. どう実装したのか?
開発当初は ERC-6900 をベースにした実装を考えたのですが、実装当時はこの提案が出てからまだ半月も経っておらず、以下の懸念がありました。
- 研究的な実装を進めたが、大幅に仕様が変更する可能性がある
- 既に実装されているモジューラブルな実装方法で実装しても、 ERC-6900 の考え方と大幅に違ってくる可能性もある
- 工数と期日が逼迫している
これらの懸念を考えると、変わらないコアな部分はどこかを見極めて、ポイントだけ押さえることが大事だと判断しました。
その結果、まずは ERC-1967 を応用した Upgrade の方式(結果的には OpenZeppelin v5.0.0 に含まれた ERC-7201 に近い状態になった)で、 Storage をロジックから切り離すように実装することを決めました。今はこのコアな部分のみ実装しつつ、将来的にモジューラブルなコントラクトに移行していきたいと考えています。
この実装自体は Soul Wallet から着想を得ており、開発当時は Soul Wallet チームが GitHub で水面下に開発していることに気づけなかったのですが、現在は ERC-6900 の考え方のサンプルの1つになりえるモジュールの構成になっています。
チーム全体としても Empower Day を活用して知識を付けていったり、PoC をつくったりなど、より良い改善に向けた取り組みが現在進行中です。
3-2. ウォレットのリカバリーについて
2つめが、ウォレットのリカバリーです。Account Abstraction を実装する上で、今ではリカバリー手段を実装することはスタンダードになっています。
しかしながら、どの方法を選択すれば提供するユーザーにとってリカバリーが実行しやすいのか?学習コストをかけずにリカバリー手段を設定できるのか?など、実生活に反映させていくには考えねばならない観点が複雑に絡み合っていると思います。
まずは技術的に、ウォレットをリカバリーするための主な手段として以下の2つを考えました。
- ソーシャルリカバリーを利用したオーナーの変更
- マルチシグを利用したオーナーの冗長化
3-2-1. ソーシャルリカバリーを利用したオーナーの変更
まず、vitalik が提唱した Social Recovery は最良のソリューションのように聞こえますが、現実的にはどのアプローチをとっても一定のデメリットがあり難しいです。
また、信頼できる家族や友人などの第三者の承認を得る、文字通りソーシャルな関係でリカバリーすることは、一般ユーザーをターゲットにするウォレットでは周りの人も Web3 に精通していない可能性が高く、実現が困難です。そのため、もう少しだけ抽象化した「本人が信頼できる Guardian を用意する・用意させる」という考え方でユーザーに届ける必要があると考えます。
各種方法はありますが、例えば OIDC を利用できる IdP を Guardian とするリカバリーが、ユーザーには一番馴染みがあって、学習コストをかけずに使用できるのではないかという仮説が考えられます。
ただ、これも良い方法に見えますが、以下のデメリットはあると考えました。
- 公開鍵の変更があった場合、ID トークン検証用のシングルトンコントラクトのデプロイが毎回必要になる
- IdP が悪意をもてばリカバリーを実行できてしまい、実質セミカストディアルな状態になる
- この問題を解決しようとすると、よりアーキテクチャが複雑になる
結果的に、現在の知見や開発のためのコストや可逆性、費用対効果を考えると、他の方法で進めるのがよさそうでした。
次に、よりコスト感と見合った現実的なアプローチとして、すでに実装されているソーシャルリカバリーや関連するロジック、Argent の SecurityManager や Safe の OwnerManager などのロジックをベースに、ソーシャルリカバリーを実装することが考えられます。
この方法は現時点においては一番現実的だと思いますが、Guardian は ECDSA で検証ができる署名を作成できる必要があり、リカバリー用の秘密鍵をどこで生成し、保持してもらうか?が課題になります。
これは今までの「EOA をいかに一般ユーザーに対して安全に保管してもらうか?」と同じ課題になり、ブラウザウォレットをこれから作る我々としては悩ましい問題になりました。
3-2-2. マルチシグを利用したオーナーの冗長化
別手段として、マルチシグの仕組みを利用してオーナーを複数用意する方法も当然考えられます。
これはオーナーを増やして 1/n のマルチシグウォレットにすることで、オーナーのどれかを失っても、別のオーナーでウォレットを管理できるようになり、実質ソーシャルリカバリーに近い考え方となるということです。ロジックの複雑さはなく、実装もしやすいように思います。
ただし、複数のオーナーを設定できるようにすると、適切なオーナーを設定してもらいたいがそれを制限することは難しいと考えました。後述しますが、投機目的でウォレットの転売に利用されないか?も考慮すると、すべてのオーナーが「ユーザー自身が管理するものである」ことを検証できる必要があります。
また、ユーザーが学習コストをかけずに用意できて失いにくい方法で、かつウォレットを利用するときの体験も良い方法でオーナーを用意してもらう必要があるのは、変わらずクリアしなければいけない課題だと感じました。
3-2-3. どう実装したのか?
つまり、解決せねばならない主な課題は2点あります。
- ユーザーに学習コストをかけずにウォレットのオーナー・リカバリーの鍵を生成してもらう
- リカバリーをするときは適切なウォレットのオーナーにローテーションできる
この2点を現時点で達成するには、ウォレットのオーナーをオフチェーンの MPC で生成するのが適切な方法ではないかと考えました。
まず、ユーザーに今までの体験と変わりなくオーナーを生成してもらうには、ソーシャルログインでウォレットを作れるのが理想的だと考えます。これは弊社のプロダクトである Fanlink のアカウントを作れば、それがウォレットのオーナーになるようにするのがベストな状態だと考えました。
また、オンチェーン上でリカバリーをするとなると、新しいオーナーをユーザーが用意する必要があります。これもユーザーにとっては、私たちから何かしらの機能を提供しないと Metamask などの EOA を用意する必要が出てくるので、オーナーは変えずに同じ Fanlink アカウントでリカバリーができるようにする、要はオフチェーンでリカバリーできるのがベストな状態だと考えました。
これらを踏まえ、現実的に取れる選択肢を考えると、Web3Auth, Lit Protocol が当時は考えられましたが、Node の監査状況やサポート状況などを鑑みて、Web3Auth の tKey MPC を選択しました。
また、リカバリーの鍵を保持してもらう手段としては、リカバリーの鍵をプログラム上で生成して、そのデータを Cloud Storage に保存させることだと考えました。
この方法では仮に Google Drive を保存先と考えると、ユーザーは Google アカウントでアプリにアクセス権を許可すればリカバリーを取れる状態になり、体験としてはソーシャルログインのフローと変わりなくリカバリーを設定できます。
これをオンチェーンの Guardian ではなく、オフチェーンの MPC で分散した鍵をリカバリーとして設定するように考えました。このスキームでソーシャルリカバリーを実装すると、オンチェーンで Guardian を設定・保持してもらうときでも同様の流れで実現できるので、オンチェーンでのリカバリーも対応できます。
参考にさせていただいた Argent や World App も同様のアプローチを取っているので、費用対効果が合っているソリューションだと思っています。
ウォレットのオーナーに関して、技術的にベストな選択をするならば、BLS や Schnorr などの集約署名を取り入れたオーナーの生成や WebAuthn を取り入れた 2Factor も導入するなど、実用性がありおもしろそうな領域はあります。
ですが、まずはユーザーに提供して本当に使いやすく Web3 の体験を楽しめるのかを確かめる必要があるため、ウォレットに関する最新技術の投入は段階的に取り組んでいく必要があると感じています。
上記に挙げた方法や理論は、数ある選択肢の一端であり、どれにも一定のデメリットがあります。ウォレットのリカバリーに関しては、これが正解だという方法はいまだなく、今後も改善が必要な分野だと思っています。
3-3. 転売の防止について
さいごに、転売の防止について触れます。Account Abstraction の利点の1つは秘密鍵を失ってもリカバリーができることですが、これは見る角度を変えると、第三者にウォレットを譲渡できるようになったということです。
3-3-1. 今までは “転売” が実質できなかった
今までの EOA では、第三者に譲渡したとしても秘密鍵を変更することはできないので、秘密鍵を知っている人、つまり譲渡した人がメモなどで秘密鍵を取っておいたら、仮に売買などを通してウォレットを譲渡したとしても確実に所有者が変わるとは言えませんでした。
ウォレットという自身の資産を管理するものを他人に受け渡すことは、実生活上では考えにくいかもしれませんが、Account Abstraction によって、このユースケースが技術的に可能になった点は、Gaudiyが考える「ファン国家」を実現するには考慮する必要がありました。
例えば、IP にまったく貢献していない人でも、ファン活動を頑張っているウォレットをお金で手に入れることができるようになるとしたら、適切なトークングラフを描けなくなってしまいます。また、投機目的のユーザーも入ってきて、ボラティリティが高くなり、本当のファンに負担がかかったり、ファンとしての熱量が下がってしまうかもしれません。
3-3-2. どう実装したのか?
これを解決するために「ウォレットのオーナーを変える処理は Gaudiy の署名も必要とする」ように実装することを考えました。具体的には、EIP-712 の署名を作成して、各メソッドで署名を検証するという、一般的なアプローチで考えました。
一方の課題として、適切なオーナーに変えようとしていることをどうやって判断するのか?は、変わらず議論しなければいけません。実装方法で他に良い方法があるとは思うのですが、今のところは IP 経済圏の公式なウォレットという状態を守るためのアプローチとなっており、その点では妥当性はあるかなと思っています。
もし、何か思いつく方・気づきがある方はぜひ議論させてほしいなと思っています。
4. まとめ
実際に取り組んでみて、今までのスマートコントラクトの開発とは違うアプローチを考えることや、現実世界で使えるレベルまで解像度をあげることは、限りある時間の中ではなかなか大変な部分もありました。この点は引き続き研鑽を積んでいきたいと思います。
また事業の特性上、完全にパブリックに開かれており、ユーザーに全主権があるという訳ではなく、どこかにルールを設ける必要があり、そのルールをどうコントラクトで定義するべきなのか?そもそも本当にルールが必要なのか?は研究とユーザー検証をしていく必要があると感じています。
べき論でいくと、ウォレットの UX を高めるためには、Starknet のようにチェーンがネイティブに Account Abstraction をサポートしていくことが必要だということも理解できますが、事業を進めることを考えると、可能な限り標準化に寄せながら、今の最善策を取っていくしかないと思っています。
ERC-4337 はまだまだ事例としては多くないですし、私たちも手探りで進めているので、もし何かシェアできるものがある方は、ぜひ教えてもらえたら大変嬉しいです。
ブロックチェーンエンジニアも募集してます。興味ある方いましたらぜひ。
また来週 11/7(火)に、Account Abstractionをデプロイする実践形式のオフラインイベントを開催するので、興味ある方いたらぜひご参加ください!