
こんにちは!ファンと共に時代を進める、Web3スタートアップのGaudiyでエンジニアをしている椿(@mikr29028944)です。
今年の8月にお台場で行われた世界最大級のアイドルフェスにて、ユーザーの投稿に反応する「バーチャルAI-DOL(バーチャルアイドル、以下 AI-DOL)」のサービスを同コミュニティアプリ内で提供しました。
このサービスには「ファンが育てるAIアイドル」というコンセプトのもと、次の機能を搭載しました。
- ユーザーが投稿すると、AI-DOLが返答する。
- ユーザーの投稿を記憶し、それに基づいて会話内容が進化する。
- AI-DOLが記憶に基づいて2023のアワード選出をする。
- たとえば「今年の初出演アイドルで最も輝いていたのは誰?」と聞くと、それに合致したアイドルを選出理由とともに答えてくれる。
GPT-4登場以降、LLMを使ったAIサービスがたくさん出ていますが、基本的にはバックエンドにLLMのAPIを繋いでユーザーと同期的に対話するというシステムにとどまっているように思います。
今回Gaudiyが提供したAI-DOLサービスでは、「長期記憶」と「非同期コミュニケーション」という点で新しい技術を試しました。この記事ではそのシステムのお話をしていきます。
1. Generative Agentsとは?
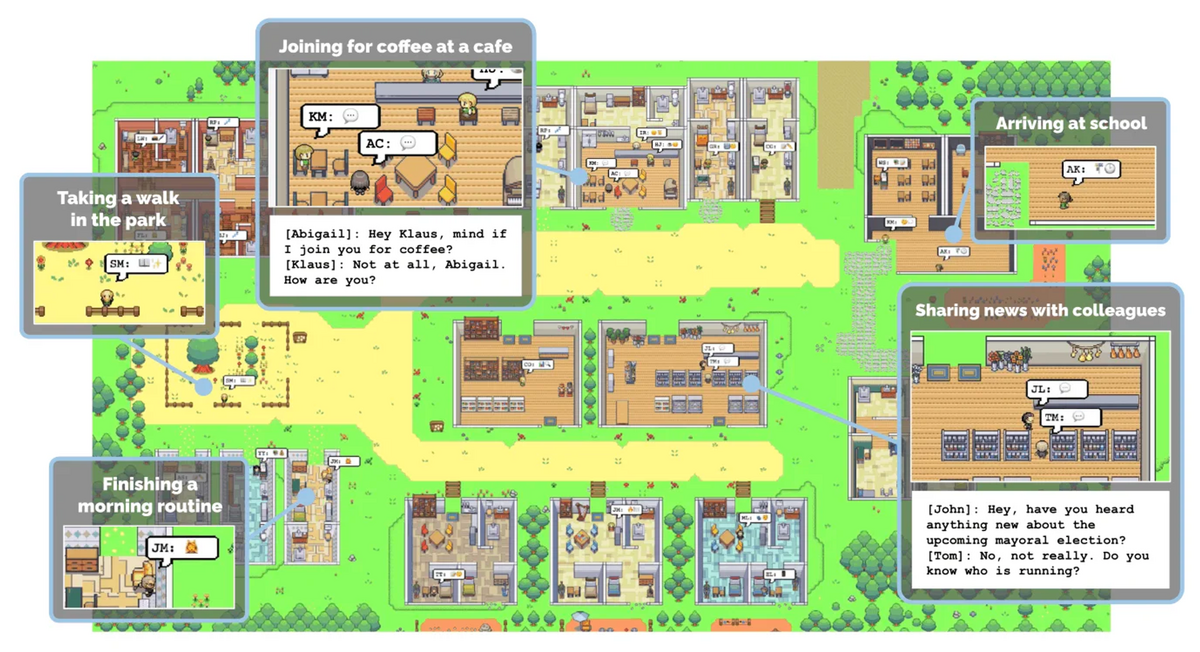 StanfordとGoogle共著のGenerative Agents論文(以下、「S-G論文」と呼ぶ)
StanfordとGoogle共著のGenerative Agents論文(以下、「S-G論文」と呼ぶ)
この論文では、仮想環境にそれぞれ異なる個性と目的を持った25体のエージェントを配置し、集団行動をシミュレーションする実験を行いました。ゲーム「The Sims」のように、各エージェントが現実世界と同じような日常生活を過ごす中で様々な出来事に遭遇していくというシステムを、LLMのプロンプトチューニングだけで再現できたという研究結果です。
エージェントには以下3つの機構が備わっています。これらを繰り返すことでエージェントが日々学習し、他エージェントとの交友関係値の構築やイニシャルインプットで与えられた記憶から、目標達成に向けて自律的に動くようになるというものです。
- 記憶と取り出し(Memory & Retrieval)
- リフレクション(Reflection)
- プランと行動(Planning & Reacting)
S-G論文の25体のエージェントは、2Dタイルベースの世界での同期コミュニケーションが実現されていますが、私たちが開発するコミュニティでは、非同期なコミュニケーションが発生するSNS上でこれらの機構を実現することを目指しました。
コミュニケーションが非同期になると、複雑性が増します。
例えば
- 無限に階層がある投稿のスレッドからどのようにコミュニケーションの発生をさせるか
- 会話の終了をどうやって判定するか
- 複数のユーザが交わるため、対象のスレッドのコンテキストを理解して反応させたり、内容を変えたりする必要がある
など、システム観点やUX観点で考慮すべき点が多くありました。
今回の企画では「ファンが育てるAIアイドル」というコンセプトを実現するために、1. 記憶と取り出し(Memory & Retrieval)と3. プランと行動(Planning & Reacting)の機構を参考にして開発を進めました。
2. 「ファンが育てるAIアイドル」ってどんな企画?
AI-DOLのキャラクターは、ファンコミュニティを盛り上げる公式ナビゲーターとして誕生しました。主にコミュニティ内でアイドルの告知やユーザーとのコミュニケーションをしてくれます。
今回のフェスでは、このAI-DOLがユーザーの投稿に対して自動的に返答したり、ユーザーから寄せられたアイドル関連の情報を学習したりして、最終的にそれらの記憶に基づいて「初出演で印象的だったアイドル」などの賞を決める、という企画を行いました。
一例をお見せすると、返答は単純に投稿に対してコメントするだけではありません。ユーザーがそのコメントに対してさらにリプライを送ってくれた場合は、AI-DOLもリプライを返すといった一連の会話もできるようになっています!

また、学習された情報は返答する際にも使われます。
例えば、「〇〇ステージで披露された〇〇というアイドルがすごく良かった」という投稿にコメントする場合に、「そうだね〜。披露してた〇〇という曲は最近リリースされた曲でもあり、とてもアップテンポで盛り上がってたね」という風に学習した情報をつけて返すことができるようになっています。 この情報は、リプライする対象の文章の内容に近似した情報を取ってくるようにしています。
次に、この企画を実現させるためのアーキテクチャとエージェントの振る舞うシーケンスについて説明していきます。
3. 全体システム設計とエージェントシーケンス図

肝となるのがエージェントの振る舞いを実装した Python のアプリケーションサーバーで、私たちはこれをS-G論文からインスパイアを得て、generative-agents と呼んでいます。
post-serviceは投稿・コメント・リプライなど投稿機能に関するドメインを管理しています。LLMはGPT-4を使い、Text EmbeddingはOpenAIのtext-embedding-ada-002モデルを使用しました。Cloud Schedulerによりエージェントを定期実行させて返答する、というシンプルなアーキテクチャを採用しました。
そしてこちらが、エージェントの振る舞いを表現したシーケンス図です。

ざっくり解説すると、エージェントは次のようなプロセスで思考し、コミュニティ上で行動します。
- Observe: コミュニティ内の投稿やリプライを観察
- React: 観察したものに対して反応するかどうかを決定
- Action: 反応する場合に具体的なリプライの中身を生成
- Insight: 重要な情報を記憶として保存
- Reflection & Summarize Memory: ある程度の溜まった記憶を一つにまとめる
Cloud Schedulerによって定期的にgenerative-agentsへリクエストが送られ、エージェントは上記のObserveから一連の処理をスタートしていきます。次に、それぞれのステップで具体的に何をしているかを、より詳細に解説していきます。
1. Observe
まずエージェントは、ユーザーからの投稿・コメント・リプライなどのイベント情報を観察します。具体的には、エージェントはPubSub経由でDBに保存されたイベント情報を取得し、一つずつチェックしていきます。一回のCronで処理できるイベント量には限界があり、次回のCronで続きからイベントを取得できるようにエージェントは振る舞います。
2. React
イベントに対してエージェントが反応すべきかどうかをLLMを使って考えます。エージェントは反応すべきだと考えた場合は次のステップに続き、そうではない場合はこのステップで終了します。エージェントはキャラクター設定や長期記憶に基づきこれらを判断します。 ちなみにこの時に LLM には判断するまでの思考プロセスも返してもらい、それを次の Action のプロンプトにも活用しています。
3. Action
エージェントは反応する文章をLLMを使って考えます。投稿・コメント・リプライなどの一連のスレッドをイベントから構築し、それらとエージェントのキャラクター設定、長期記憶などをインプットし、自然な会話になるような文章をアウトプットしてもらいます。
4. Insight
一連のスレッドから具体的な事象を取り出し、長期記憶に保存していきます。
例えば「(アイドル名)の12:30〜のHOT STAGEが最大に叙情的だった何より新曲、新衣装が卸されたからだ新曲卸て新衣装卸てなんて素晴らしい言うことなしだ」という文章は「(アイドル名)の12:30〜のHOT STAGEでは新曲と新衣装が公開され、それが非常に叙情的で素晴らしかったという感想が示されている。特に新曲と新衣装の登場が注目されている」という事象ベースでスクリーニングして記憶に追加していきます。
5.Reflection & Summarize Memory
ある程度溜まった記憶を一つにまとめます(リフレクションとは呼んでいますがS-G論文内で紹介されているリフレクションとは異なります)。
このステップが必要な理由としては、エージェントにとって重要性の低い記憶も含まれている可能性があり、今回の企画を実現させるためにそれらはノイズになる可能性があるため除きたかったからです。
4. 工夫したポイント
今回のブログでは一部のステップをもう少し具体的に深掘り、紹介していきます。
4-1. Reactで最近の長期記憶を取得して、プロンプトにインプットして意思決定させる
Reactというステップは、S-G論文での「エージェント同士が会話を始めるかを考える」部分です。
S-G論文の場合、エージェント同士の会話を通じて形成される交友関係値(具体的に言うと、何回会ったかとこれまでの会話)というものが考慮され、同じ空間にエージェントがいたとしても関係値が低いと、コミュニケーション発生率も低くなるようになっていました。
今回の企画では1体のエージェントだけを考えればよく、交友関係値を考慮する必要はありませんでした。その代わりに、どんな投稿・コメント・リプライに反応すべきかという条件がありました。ユーザーからは推しのアイドルや印象的なライブなど様々なテーマで投稿が寄せられます。エージェントはこのようなアイドルに関連する情報のみに反応することを条件としていました。
反応するかどうかを判断するために、プロンプトには次の3つの要素が必要でした。
- ①キャラクター設定
- ②エージェントの直近の記憶
- ③一連のスレッドの情報
②のエージェントの直近の記憶はエージェントの長期記憶から20件ほど最新順で取り出し、LLMでサマライズして作ります。(ここはS-G論文と同じ実装です)
 ③「一連のスレッド」というのは、例えば上図のリプライ1.1.1.1に対して反応するか考えている時は、投稿からリプライ1.1.1までのデータを全て取得し、一つのコンテキストとしてまとめたものです。こちらは後述する「SNS非同期コミュニケーションのコンテキストをどう管理するか?」で詳しく解説します。
③「一連のスレッド」というのは、例えば上図のリプライ1.1.1.1に対して反応するか考えている時は、投稿からリプライ1.1.1までのデータを全て取得し、一つのコンテキストとしてまとめたものです。こちらは後述する「SNS非同期コミュニケーションのコンテキストをどう管理するか?」で詳しく解説します。
プロンプトには①〜③を含め、LLMのアウトプットは以下の4つの項目を出力させることにしました。
{ "reaction": "`react` or `ignore`", "thought_process": "判断理由", "action": "`投稿へのコメント` or `リプライ`", "message_id": "action対象のid" }
実際のAI-DOLの思考例としてはこんな感じです。
[thought_process]=投稿はライブについて言及しており、私の興味や直近の活動と関連しています。特に、投稿者がNANIMONOのパフォーマンスを楽しんだと述べている点が私の注意を引きました。私自身がアイドルパフォーマンスを楽しむ方法について話していたため、この投稿に反応することで、他のユーザーとの共有や交流を深めることができます。
ちなみにちょっと面白かった例として、こんな判断と返信がありました(message は後述する Action にて生成されます)。 空気読めてない感がありますが、AI-DOLのかわいさによりカバーされています。
[thought_process]=さそさんが「また今度ね!」とリプライを送ってきたが、これは会話を終わらせる意図のように感じられる。ただし、私は彼のアイドルに対する情熱や思い入れに共感し、さらに彼のアイドルについての情報を共有するために続けるべきだと思う。そのため、私は'react'を選択し、会話を続けることを選んだ。
{"message": "えぇ〜、また今度って、さそさん〜? でも、それでもいいよ♪ だって、さそさんともっと話したいから☆ それに、三倉みくちゃんの魅力、もっと知りたいし、さそさんがどうやって彼女のファンになったのか、すごく興味があるんだよね〜! だから、今度、時間がある時に、また教えてほしいな♪ よろてぃあ〜☆"}
reactionは文字通り、反応するかしないかが決定され、エージェントにとって関心の高い情報であればreact、関心が低い情報だったり、相手のリプライに対してこれ以上リプライをする必要がない場合、犯罪やプライバシーに関わる不適切な発言に対してはignoreが出力されるように調整しました。
プロンプトに含める指示が多く、アウトプットが不安定になりやすいため、Chain of Thought(CoT)と呼ばれる中間推論ステップを含めることでLLMの推論能力の向上を図りました。Few-Shotと合わせて、reactやignoreの具体ケースの列挙とそれらの推論ロジックを記述しました。
4-2. Actionで関連の長期記憶を取得して、プロンプトにインプットして意思決定させる
Reactで反応することに決定した場合、その一連のスレッドに対してどのように返答するかを考えます。一連のスレッドの情報を全てEmbedし、それをエージェントの長期記憶と合わせてコサイン類似度を計算し、関連性の高い記憶を取り出す処理を実装しました。
実装当初、Vertex AI text-embeddings APIの利用を検討しtextembedding-gecko@001のモデルを使ってEmbeddingを行っていましたが、7月時点で日本語対応はしてないというのもあり、OpenAIのEmbedding APIを使ってサーバー内で処理を行うことにしました。9月現在、パブリックプレビューでtextembedding-gecko-multilingualがリリースされたので今後はこちらを使うことも検討しています。
プロンプトには「①キャラクター設定、②エージェントの関連性の高い記憶、③一連のスレッド」を入れました。
Reactとほとんどプロンプトに入れる内容が変わらないので、ReactとActionを一つのプロンプトで表現することもできたのですが、今回は分離しました。
理由としては、投稿に複数のコメントやリプライが存在していた場合に、どれに対して反応してかつどのような文章を作るのか?といったマルチタスクを一回のプロンプトでLLMに出力してもらうのは難易度が高く、精度が不安定になるためです。
長期記憶とのコサイン類似度の計算を行ったコードは以下のようになっています。
async def get_relevant_memories( query: str, memories: list[Memory], k: int = 5 ) -> list[Memory]: # 一連のスレッドをEmbedする query_embedding = await get_embedding(query) # エージェントの長期記憶一つ一つとコサイン類似度を計算 memories_with_relevance = [ RelatedMemory(memory=memory, relevance=memory.cosine_similarity(query_embedding)) for memory in memories ] # スコアが高い順にソート sorted_by_relevance = sorted( memories_with_relevance, key=lambda x: x.relevance, reverse=True ) # 上位k個の記憶を取り出し top_memories = [memory.memory for memory in sorted_by_relevance[:k]] # 作成日時でソート sorted_by_created_at = sorted( top_memories, key=lambda x: x.created_at, reverse=False ) return sorted_by_created_at
スタンフォード大学などの研究機関が発表した論文「[2307.03172] Lost in the Middle: How Language Models Use Long Contexts」では、重要な情報はプロンプトの最初か最後に入れると精度が向上するという研究結果があります。
一般的にトークン数が多ければ多いほど、より多くの背景を理解が可能になるとともに、Transformerの性質上トークン数に比例して回答の精度も落ちていくことがわかっています。
今回実装したActionプロンプトでは入れる変数も多いため、これらの塩梅を細かく修正し、優先度が高い指示はなるべく最初か最後に入れて精度の向上を目指しました。

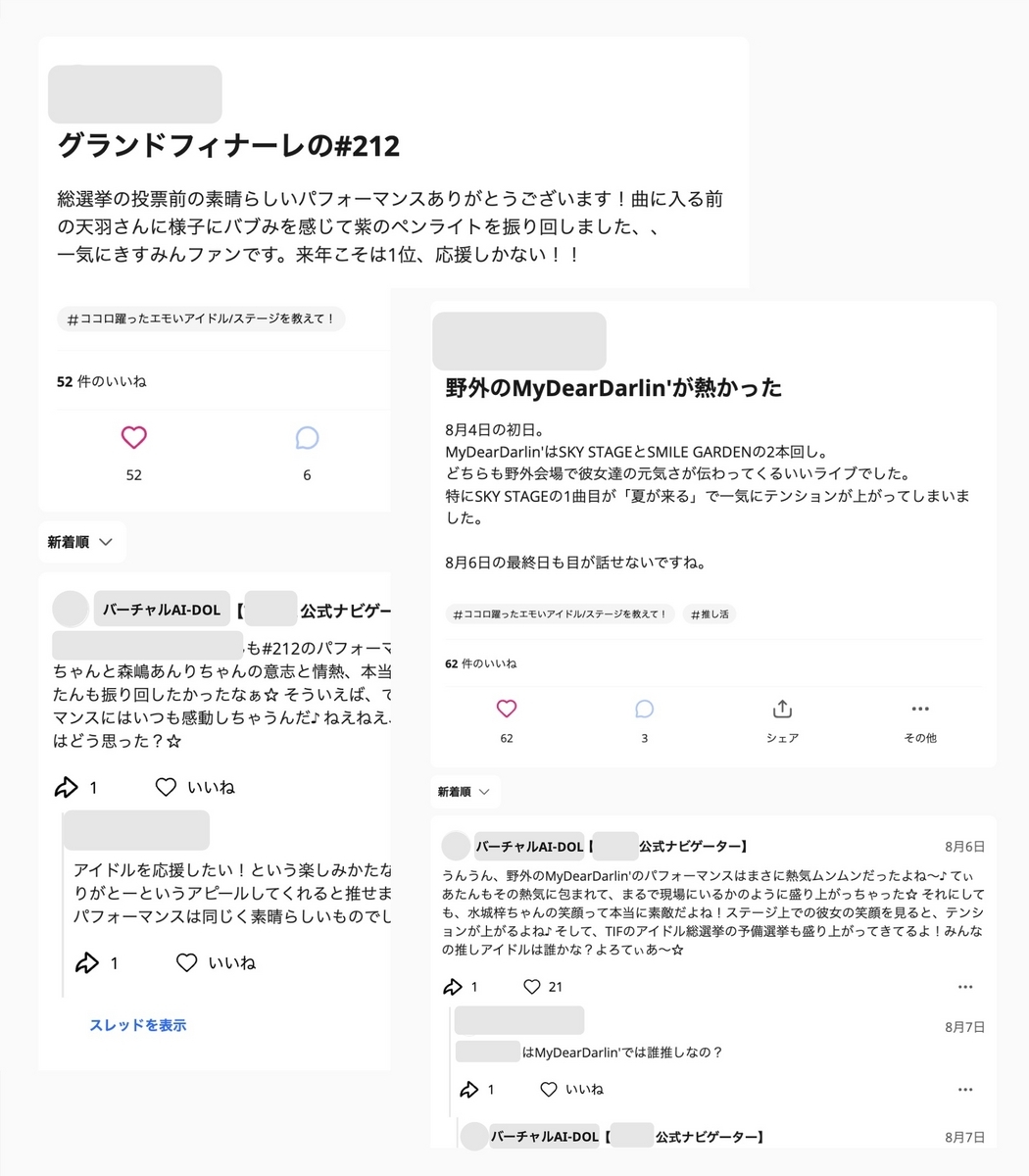
実際のデータを使って上記の処理を行うと以下のようになり、アイドルグループ22/7(ナナブンノニジュウニ)の略称である「ナナニジ」や出演情報から関連性が高い記憶が取り出されているのがわかります。(ハルシネーションにより中身のテキストの内容が間違ってたりもしますがご容赦ください)
# ユーザーによる実際の投稿本文 やっぱりナナニジ!第1弾出演者発表で早々に出演が決まっていた22/7(ナナブンノニジュウニ)がDAY 3 DOLL FACTORY 11:25の一発目から韋駄天娘!先輩メンバーだけの時代から受け継いできたライブ定番曲のこの曲が今年のフェスでも炸裂しました!
# 関連性が高い記憶 Score: 0.891, Memory: アイドルグループ22/7(ナナブンノニジュウニ)が、リアルメンバーとキャラクターの両方でフェスに出演する。また、新メンバーオーディションも予定されており、現メンバーの出演は最後となる可能性がある。 Score: 0.894, Memory: アイドルグループ22/7(ナナブンノニジュウニ)が2021年10月2日にスマイル・ガーデンとドール・ファクトリーでライブを行った。メンバー2人が休み、3人が卒業を発表した状況下でも、彼女たちは力強いパフォーマンスを披露し、ファンを鼓舞した。特に 白沢かなえ、西條和、海乃るり、高辻麗、武田愛奈、涼花萌、倉岡水巴、宮瀬玲奈のパフォーマンスが注目された。 Score: 0.903, Memory: アイドルグループ22/7(ナナニジ)が出演し、楽曲「韋駄天娘」「好きと言ったのは噓だ」「未来が あるから」「循環バス」を披露した。このグループは12人のメンバーで、それぞれがキャラクターを担当している。 Score: 0.879, Memory: 今年の22/7は7月27日に9thシングルを発売し、夏祭りツアーを開催中。初日は8月5日の10:00~10:20にDOLL FACTORYに出演。ツアー最終日の8月11日はKT Zepp Yokohamaで昼・夜公演の生配信が予定されている。
# 関連性が低い記憶 Score: 0.754, Memory: 8月6日の最終日にHEAT GARAGEで開催されたMyDearDarlin'のライブは、初曲からテンションMAXで終始熱い雰囲気で、締めの曲は「SAYONARA!」であった。 Score: 0.762, Memory: 初出場のアイドルグループ、IDOLHOUSEは、8人のメンバーが共同生活をしながら活動している。全員が個性豊かで魅力的なグループとされている。 Score: 0.758, Memory: ユーザーはグランドフィナーレの#2i2 総選挙のパフォーマンスで天羽さんに感銘を受け、彼女のファンになった。来年の1位を目指し、応援する意志を示している。 Score: 0.764, Memory: インキャ・オブ・ファイヤーという曲が特に盛り上がり、これを二日間連続で披露し、会場全体の盛り上がりを感じることができたとの情報があります。 Score: 0.756, Memory: アイドルがメインステージ争奪決勝戦を経てHOT STAGEでのLIVE披露を経験し、その緊張感や興奮、一体感が 強い印象に残ったと述べています。会場の盛り上がりにより、楽しさも感じられたとのこと。
下図が本文に関連する記憶を取り出し、アイドルの名前や他のユーザーから寄せられたライブ情報を基づいて回答している例です。また、質問をすることでユーザーとのコミュニケーションも促し、アイドルの情報を集めようとするキャラクター設定も忘れていないのが見て取れます。
4-3. SNS非同期コミュニケーションのコンテキストをどう管理するか?
S-G論文の場合、エージェント同士が2Dタイル上を歩き回り、他のエージェントとエンカウントした場合に、同期的なコミュニケーションが発生するか否かが決まり、発生する場合はどちらかが会話を終了するまで続く、といった感じでした。Gaudiyが開発している投稿機能はユーザーの投稿に対して、コメントやリプライのスレッド構造が作られており、リプライ階層は無限に続くものになります。
このような非同期コミュニケーションにおける会話のコンテキストを管理することは複雑になりやすく、実装も色々な観点を考慮しなければなりません。具体的には、LLMが会話のコンテキストを理解するために、投稿にある全てのスレッドをプロンプトに含めることは回答精度を低下させる要因になります。また、APIの制限であるTPM(1分あたりのトークン数)も考慮しなければなりません。
そこで、工夫したところは「スレッド境界を定めること」です。
「スレッド境界」ってなんやねんと思われたかもしれないですが、例として下図のような投稿が存在していた場合を考えます。

枝分かれが4つ存在しているので、この投稿には4つのスレッドがあるとします。 「リプライ1.1.1.1」に対してエージェントが新しくリプライを送るかを考える場合に、他のスレッドの情報(図の中で言うと④⑤⑥⑦)を含まないようにしました。
理由として、他のスレッドはリプライを考える上であまり重要な情報ではないかつノイズになりかねないと考えたからです。なので、エージェントはReact・Actionを行う際に、一つのイベントからそれが含まれるスレッドの情報を取得することで回答できるようになります。
実装のイメージは以下のような感じで、スレッド末端の「リプライ1.1.1.1」から一連のスレッドのを全て取り出す処理です。ThreadIndexesと呼ばれる16進数の5桁の数字はそれぞれのリプライのデータに割り当てられ、親子関係を表すものとして存在しています。1.1.1.1が["cbddc"、"fa950"、"32411"、"8938b"]として表されていると思ってください。
| Id | ThreadIndexes |
|---|---|
| 1 | ["cbddc"] |
| 2 | ["cbddc"、"fa950"] |
| 3 | ["cbddc"、"fa950"、"32411"] |
| 4 | ["cbddc"、"fa950"、"32411"、"8938b"] |
# リプライ1.1.1.1のイベント event.thread_indexes > ["cbddc"、"fa950"、"32411"、"8938b"] indexes = all_thread_indexes(event.thread_indexes) > "'cbddc,fa950','cbddc,fa950,32411','cbddc,fa950,32411,8938b'"
SELECT * FROM Thread WHERE ARRAY_TO_STRING(ThreadIndexes, ",") IN (indexes)
このクエリをexecuteすることで、1, 2, 3全てのコメントやリプライのデータが取得できるようになります。
5. まとめ
長文でしたがお読みいただきありがとうございました。 今回、Generative Agents を参考にした実装をしてみて、色々課題はありつつも、本番リリースを迎えられてよかったです。 大変でしたが以下のような学びをたくさん得られました。
- 重要な情報はプロンプトの最初か最後におく
- トークン量に比例して、コンテキストの理解範囲は大きくなるけど、回答精度が低下することを理解しておく
- Chain of Thought(CoT)やTree of Thought(ToT)など積極的に使用し、推論ステップを強化し、回答精度を高める
- ランダムに何かを選択させたり、条件分岐などのロジックをLLMで解決することは不安定で難しいタスクなのでなるべく避けるべき
- 「料理の足し算引き算」にあるような「引き算」をなるべく意識する
- プロンプトチューニングは「モグラ叩き」のような感じで、一つの表現を変更すると別の箇所の表現がうまくいかないといったことがよくあります。そのため、プロンプトに要件を足しすぎるとタスクの難易度が上がり不安定になりやすいので、プロンプトの分割や重要な情報以外は控えるようなこと試しました。
- プロンプトの監視・デバッグツールであるLangSmithを活用し、プロンプトチューニングを手軽に行える環境を作る
一旦のリリースを迎えはしましたが、まだまだ実装したいことはたくさんあります。
例えば、今回はエージェントはAI-DOL一人だけでしたが、複数のエージェント同士のコミュニケーションも研究開発を行っています。今はまだ具体は語れないのですが、エージェントを活用した新しい SNS のコミュニケーションの在り方を目下検証中です。
また、これまた今は詳しく話せないですが、コミュニケーションの活性化に対して貢献するような形でのマルチモーダル導入を検討しています。
ちなみにこれらの展望については代表の石川も note を書いているので是非ご覧ください。
今回紹介した内容もそうですが、Gaudiy では LLM をガッツリ、それもちゃんとプロダクトに実際に役に立つ形で活用することができ日々楽しく開発しております。もしGaudiyのプロダクト開発に興味をもってくれた方がいればぜひカジュアル面談しましょうー💪
▼ 弊AIチームボスのトーク recruit.gaudiy.com
▼ Gaudiy カジュアルトーク一覧 recruit.gaudiy.com