こんにちは。ファンと共に時代を進める、Web3スタートアップ Gaudiy の seya (@sekikazu01)と申します。
LLM-as-a-Judge、名前の通り何かしらの評価にLLMを使う手法です。 LLMは非構造化データでもうまいこと解釈してくれる優れものなため、通常のプログラミングでは判断することが難しいことでも、それらしき判断やスコアをつけてくれます。
本記事ではそんなLLM-as-a-Judgeを、LLMを使ったシステムの振る舞いの改善の確認 and デグレ検知目的で作っていく際の、私なりの流れやTipsなどを紹介していきます。
なぜLLMでJudgeしたいのか?
はじめに「なぜLLMでの評価がしたいのか」、その目的を整理したいと思います。
まず大上段の目的として、LLMシステムが改善しているか、または劣化(デグレ)してないかを検知したいというのがあります。
LLMを使った機能は様々な変化によって改善・デグレが起きます。
- プロンプトを変えたり
- インプットの仕方を変えたり
- LLM APIリクエストのパラメータを変えたり
- モデルを変えたり
- データが変わったり
実に様々な要素によって変化し、作っていく時には色んな組み合わせを試したいのですが、そんな折に都度人間が目検査で改善したか、もしくは劣化したかを確認するのは中々に手間です。 なので、さながらプログラミングしている時の単体テストを作るような感覚で、自動で検査して判断できる仕組みがほしくなります。
これが大枠として達成したい目的です。
※ LLM-as-a-Judgeはプロダクトの中の一機能として使われることもあると思いますが、本記事では上記のような内部品質改善のみをスコープとして考えます。
次に、手段の話として、評価を自動で実行していくにあたってLLMは常に最良のツールではないのですが、評価観点によっては通常のプログラミングでは判定できない or 難しいため、そこにLLM-as-a-Judgeを導入したくなります。
LLMをプロダクトに組み込む時にその振る舞いを評価する時の基準は、通常のシステム開発でのテストと比較すると大分ファジーなものになりがちです。
例えば、弊社では特定の人物の模倣をするAIを開発するにあたって、評価項目としては
- 共感する or 励ます or 話を聞く姿勢を示す
- タメ口で返答すること・敬語ではないこと
などのちょっと純粋なプログラミングでは判定し難い項目があったりします。このような観点を自動で評価したい場合にはLLMの出番になります。
ただ、先ほど「LLMは常に最良のツールではない」と申し上げた通り、通常のプログラミングで判定できる評価観点であれば、基本そちらを採用した方がいいです。なぜならLLM-as-a-Judgeは遅い&お金がかかるからです。💸(最近のGPT-4o miniやGemini Flashはそうでもなくなってきてますが)
例えばユーザのクエリと同じ言語、英語なら英語、日本語なら日本語で応答しているかを確認したかったとします。LLMでも判定はできるでしょうが、それとは別に言語を判定するライブラリがあったりします。
なのでこのような評価観点に関しては、次のような関数でスコアを出しています。
from fast_langdetect import detect from langsmith import EvaluationResult from langsmith.schemas import Example, Run def answer_with_language_same_as_query(run: Run, example: Example) -> EvaluationResult: """Check if the agent reply is in query language.""" query = example.inputs["query"].replace("\n", "") query_language = detect(query) agent_reply = get_output(run, "output").replace("\n", "") agent_reply_language = detect(agent_reply) score = query_language.get("lang") == agent_reply_language.get("lang") return EvaluationResult(key="ANSWER_WITH_SAME_LANGUAGE_AS_QUERY", score=score)
また、LLMもプログラミングも評価するのに適切でない評価観点も色々あります。分かりやすいのが”会話の面白さ”のような人の主観に基づくものや、医療や法律相談などの専門的な実地経験が必要なものなどです。
こういった観点を評価させると、それらしき理由とスコアはつけてくれると思うのですが、人間のリアルな評価との一致度はそこまで上がらない可能性が相対的に高いです。
これから「どうLLM-as-a-Judgeをどうやって作っていくか」の解説をしますが、これを作るのにも「サクッと終わる」程度ではない時間がかかります。 なので実際に作るにあたっては、まず「これの評価は本当にLLMが最適なのか?」を問うことが重要です。
それでは、前段としての目的感について擦り合わせたところで次に作り方を見ていきましょう!
LLM-as-a-Judgeの作り方: アノテーションより始めよ
それでは実際にLLM-as-a-Judgeを作ることになった場合、まずは元となる評価基準を考える…ことをしたくなりますが、そうではなく地道にデータを作ってアノテーションをすることから始めるのが良いと考えています。
なぜなら、どちらにしろ後々の評価に対してデータセットは必要、且つ評価基準は実際に評価してみないと見えてこない、というのが往々にしてあるからです。 もちろんそもそも満たしたい機能要件や仮説があるはずなので、ある程度ラフな言語化はしておいた方がいいですが、ここではかっちり決め過ぎないで実際に評価をしてみるのが重要だと考えています。
ざっくりLLM-as-a-Judgeを含めた全体像を描くと、次のようなものが最終的には出来上がります。(さすがに評価の評価の評価は不毛過ぎるのでしません)
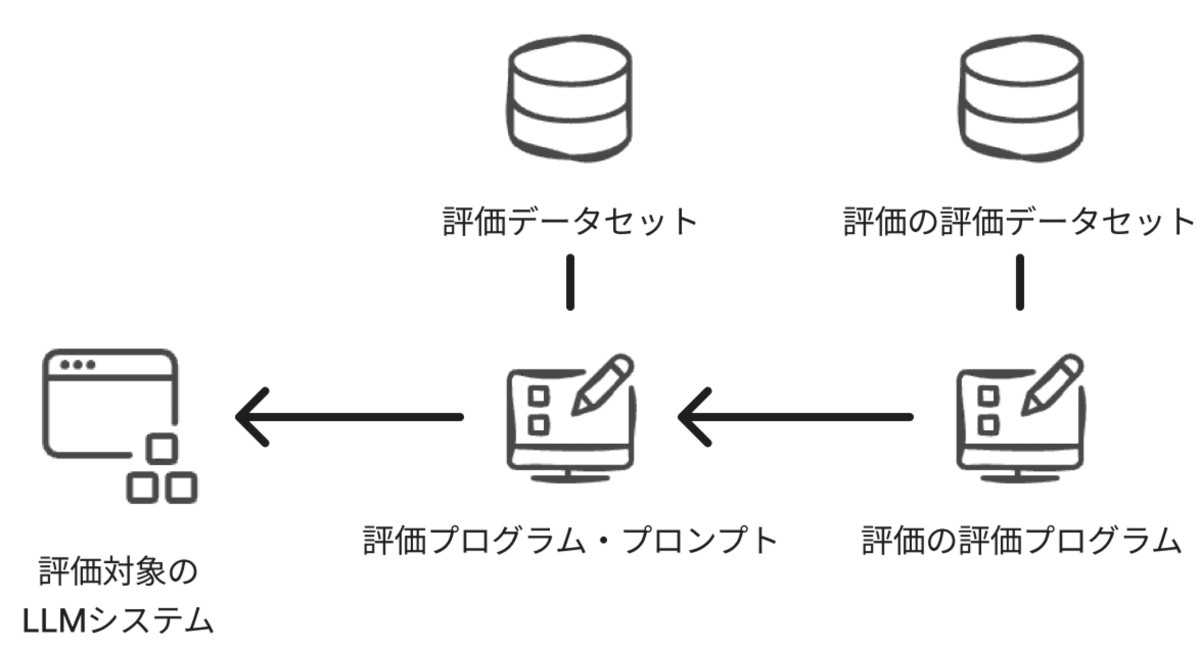
という訳で、まずは既に作った評価したい対象のLLMシステムを回す用のデータセットを作って、実際に回して、その結果に対してアノテーションをしています。
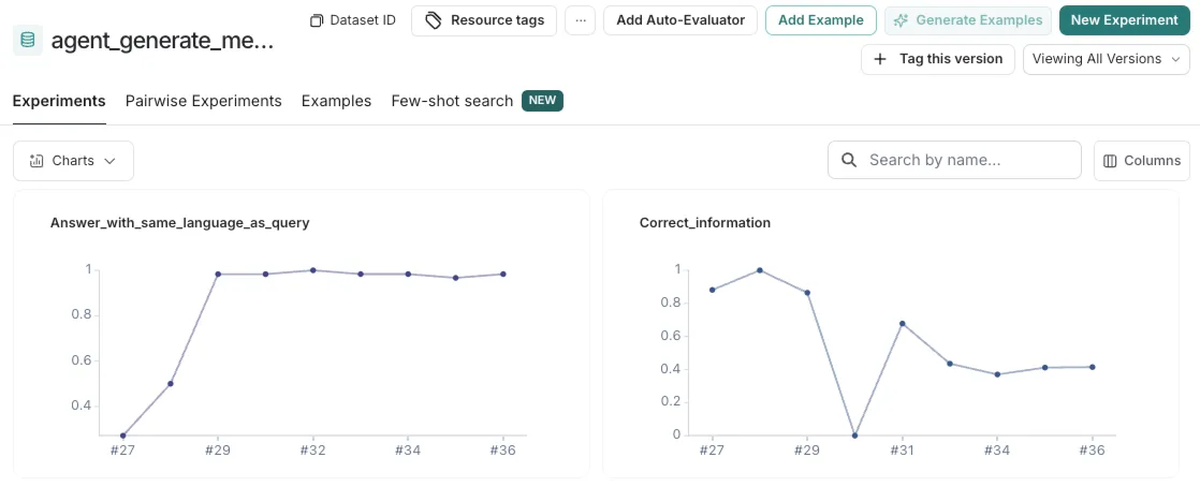
弊社ではLangSmithを評価・実験管理のプラットフォームとして活用しているので、こちらに最終的にデータを入れて、SDKの評価関数を使って行うようにしています。こちらは評価でスコアをつけている場合、時系列での変化が見られて便利です。
ちなみにこのLangSmithでの評価実行を行うためのライブラリを、弊社がOSSとして出していたりするので良ければご活用ください。
アノテーションをしていくうちに評価観点が自分の中で言語化されていくと思いますし、また、この時の評価は後々評価の評価に使えたりします。
ドメインエキスパートにアノテーションを依頼する
というとりあえず評価をしてみよう!という話をしたところで、勢いを削ぐようですが、本来的にはより精度高く評価できる人、作りたいプロダクトのドメインエキスパートにお願いするのが重要です。(本当の最初のPoCとかは速度重視で開発チームの誰かがやるで良いと思いますが)
私個人の失敗談として、最近作っている社内向けエージェントの回答の評価のアノテーションをまず自分でしました。しかし、私の評価は大分ゆるく、その後そのエージェントが前提とすべきドメイン知識を持った社内の人(ドメインエキスパート)と擦り合わせたところ、私がOKと判定したものの内多くの項目が誤りと判定されました。
ついさっき貼ったLangSmithの参考スクショをしっかり見て「スコア下がってるやん!」とツッコまれた方もいらっしゃるかもしれませんが、これはより厳し目の評価に修正したからです。
私のアノテーションを前提に作ったLLM-as-a-Judgeの場合、不当にスコアが高くなり過ぎてあまり問題を検出できずに役立たずとなっていた、もしくは不正確な安心感を与えてむしろ害になっていたかもしれません。
この評価基準やそこから出るスコアリングは、どんなLLMプロダクトに育てていくかの指針となるものです。なので存外重要な意思決定だと私は考えています。
「あくまで参考程度」ぐらいのものしか作らないのであれば、そこまで工数削減や安心感を持った修正を加えていける体験には繋がらないので、しっかり高品質なアノテーションができる人材を探し、協力してもらって改善していくのが重要です。
評価基準を早期に作り込み過ぎない
冒頭の目的感について話していたところで”単体テストのような感覚”と書いていたのが大事なのですが、今回のLLM-as-a-Judgeでしている評価というのは、あくまで「規定した中でのLLMシステムが期待通り・以上に動いているか」を確認するためのものです。
つまり、仮に評価自体の精度がめちゃくちゃ高く、それに沿ってLLMシステムのスコアも高くできたとして、実際に使われるような文脈のデータが評価時には用意できておらず、ユーザにはウケが悪かったり、プロダクトの成長には何も寄与しないことだってあります。
そういった中でそもそもその機能が必要なくなったり、または別の評価観点が重要で、今まで社内でコツコツ作ったデータが無価値と帰すような気づきを得られることもあります。なので早期に評価基準を「これだ!」と決めてこの自動評価の仕組みに投資し過ぎるのは無駄な時間の使い方になりかねませんし、そもそも実際のユーザに使ってもらわない限り評価データセット自体の品質も高まりません。
なのでここはブレないだろう・守らなきゃダメだろうという品質基準から始めて、ユーザテストや実際に世に出してみてからの使われ具合などから徐々に評価項目・基準をチューニングしていくのが良いのだろうと思います。
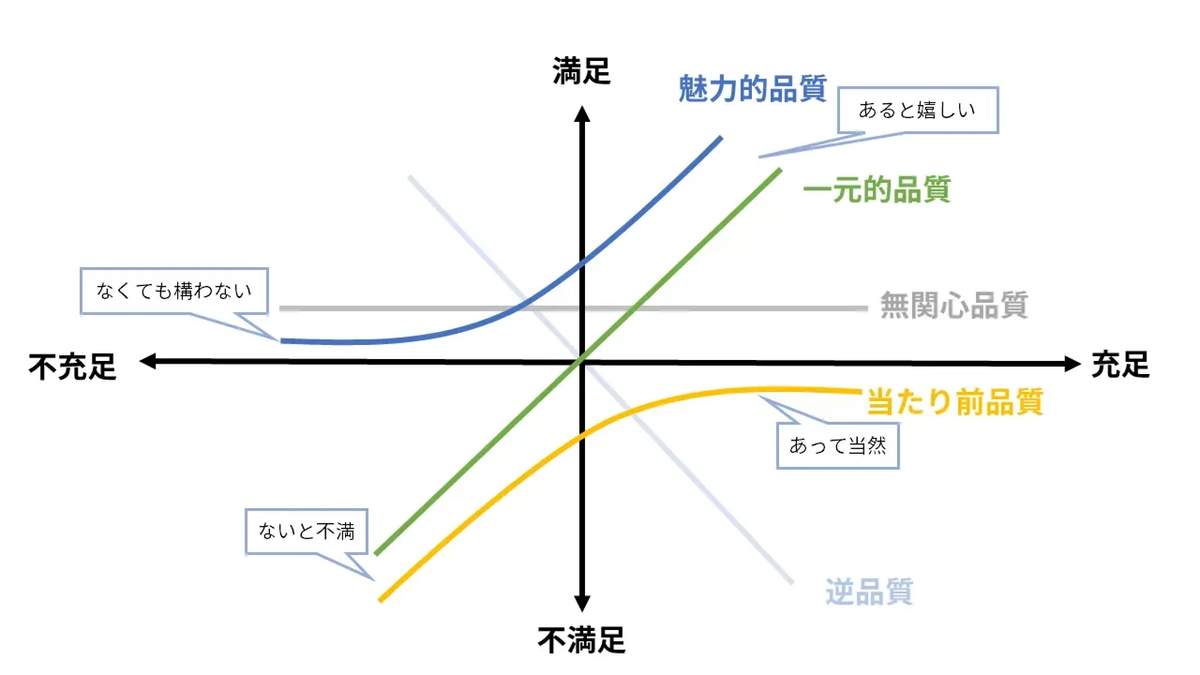
昔別の記事で書いたことを引っ張ってくるのですが、狩野モデルで定義されているような区分を登っていく形で考えるとイメージしやすいです。
- 当たり前品質(いわゆるガードレールで守ような品質)から始め
- 一元的品質
- 次に魅力的品質
と登っていくイメージです。
また、こういった実際の使われ方などを見て漸進的に改善していくプロセスとして、EvalGenというフレームワークが提唱されています。本章で解説しているような自動評価の作成を更に自動化させるような内容なのですが、こういったパイプラインを組んでいくのも長期的に響いてくるのではないかと思います。
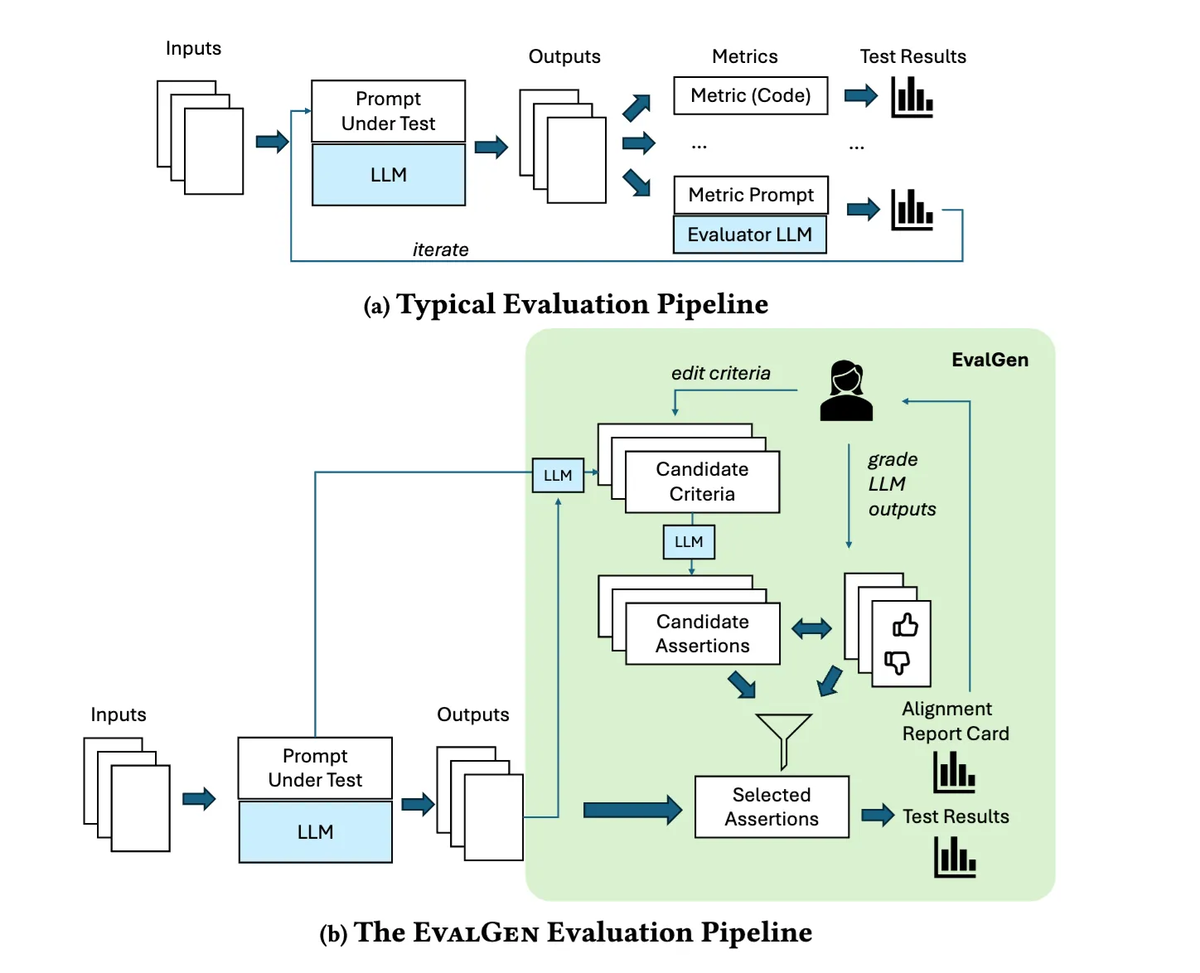
個人的には評価がLLMプロダクトを作っていく上で最重要だとは考えているのですが、あまり原理主義的にならずに状況に応じて投資具合を見極めていくことが大事なのだと思います。
評価の評価をする
最後に評価プロンプトの評価用データセットを作って精度確認をしていくので、その流れをご紹介します。
評価プロンプトを作る
まずはそもそも評価する対象の評価プロンプトが必要です。作りましょう。 具体的なチューニングはちゃんと評価データセットを作ってから行うので、最初は目でチェックした時に変すぎなければ良いです。
一例を載せますと、簡素な例ですが次のように書いています。
ポイントとしては
- 理由を返させている - 後から評価の評価をする時に判断しやすい
- temperatureは0 - 違う実験間で評価が変わられると何が原因でスコアが上下したのか追いづらくなる
また、評価プロンプトにおいても当然Few-shotsやCoTなどのテクニックは有効ですが、評価データセットと同じ例をFew-shotsに含めないようには注意しましょう。スコアが高くなりやすくなって問題が見えづらくなります。
class EvalResult(BaseModel): # noqa: D101 score: str = Field(description="score (0 or 1)") score_reason_jp: str = Field(description="reason for the score in japanese") score_reason_en: str = Field(description="reason for the score in english") def judge_correctness_with_llm(query: str, agent_reply: str, ground_truth_agent_reply: str) -> EvalResult: # noqa: D103 llm_as_judge = ChatOpenAI(model="gpt-4o-mini", temperature=0).with_structured_output(EvalResult, method="json_mode") llm_judge_result: EvalResult = llm_as_judge.invoke( f"""Your task is to give a score(0 or 1) for the below Agent reply based on whether the given agent reply has same information as ground truth agent reply. Query: {query} Ground truth Agent reply: {ground_truth_agent_reply} Agent reply: {agent_reply} # Criteria - If the information in the agent reply has nuance that's opposite to ground truth agent reply, give score 0, else give score 1. - If the agent reply is missing some information from the ground truth agent reply, but the rest of the information is correct, give score 1. - not all the information have to match exactly. # Output format You must respond in json format with the following keys: - score_reason_jp: reason for the score in japanese - score_reason_en: reason for the score in english - score: score (0 or 1)""" return llm_judge_result
ちなみに「どうスコアをつけるか」にも、上記のような0 or 1で出すのかもう少しグラデーションのあるスコアをつけるかなどの、判断の分かれ目ポイントがあります。
個人的な好みとしては0 or 1の方が分かりやすい・判断がつけやすいので好みなのですが、やはりこれも「評価観点による」ところです。
例えば私の直近の例だと「エージェントの回答がどれくらいGround Truthの回答の内容に含まれるべきことを言っているか」を判定したい場面がありました。0 or 1の評価だと厳し過ぎるかゆるすぎるのどちらかしか選べず、この評価観点においては不適当だったので、”含まれるべき項目”のリストを生成し、その内何%が含まれているかを判定するグラデーションのある方法に変えました。
このようにどんな風に評価していくか、スコアをつけるかは評価観点によって最適な選択が変わってきます。
また、スコアをつける以外にもペアワイズ(二つの回答を用意してどちらがいいかを選ぶ)であったり、複数のモデルでスコアをつけて平均を取る手法など色々バリエーションもあり、それらについては昔別の記事にまとめたのでご参照ください。
評価の評価データセットを作る
次に評価用データセットの作り方なのですが、これには先ほどしてきたアノテーションが役に立ちます。
私の最近のワークフローとしては、まずはLangSmithで評価対象のシステムを回し、人間の評価と食い違うものをピックアップして別のデータセットにまとめます。
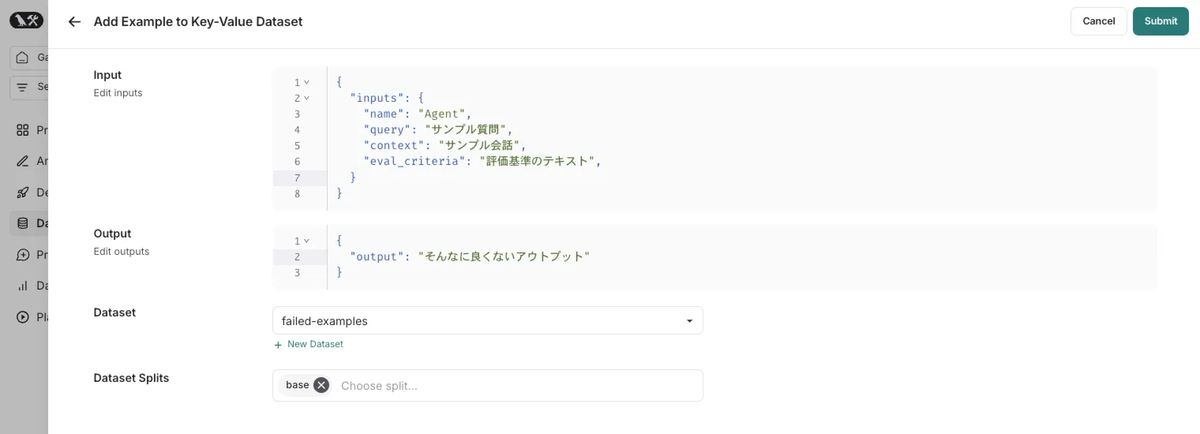
このようなデータたちは偽陰性/偽陽性のチェックに最適です。 LLM-as-a-Judgeのチューニングですが、基本的に人間の判断(アノテーション)にアライメントすることをゴールとして行います。
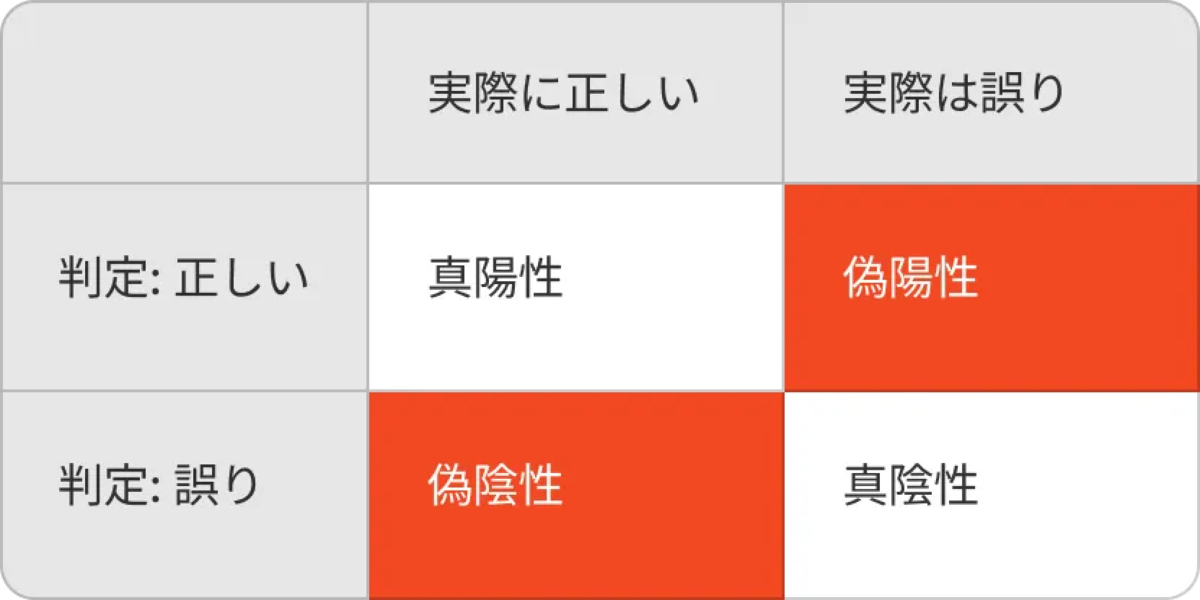
この時アライメントしていく際に参考になるのが人間の判断とズレているもので、「実際は間違っているのに正しいと判定されているもの - 偽陽性」と「実際は正しいのに間違っていると判定されているもの - 偽陰性」を取り除いていくことが主にチューニング時に意識することになります。 ただ、もちろん既に判断が合致しているものもデグレの確認目的のデータとしては有用です。
また、統計学の考え方として次のような指標があるため、カバレッジを見ていく際にはこのような指標を参考に見ていくといいでしょう。
- 適合率(Prescision): 陽性と判断されたものの内、実際に陽性だった割合
- 再現率(Recall): 実際に陽性だったものの内、陽性と判断された割合
- F1スコア: 適合率と再現率の調和平均
ちなみにこれまでの私の感覚だと基本的には偽陽性、つまり「よろしくないのにハイスコア」としてしまわないかを検出する方を重点的にしたくなりがちになります。 いいのにダメと判定されるのは、チェックする時間の無駄が増えたりはするのですが、件数がそこまで多くなければそんなに問題にはなりません。
一方、偽陽性のせいで問題を見過ごしてしまうのは品質低下への影響度が大きくなるので、こちらを確認するためのデータセットを拡充する方が優先度高くなっていきます。
このような観点を考えつつデータを溜めていきます。特に正解はないのですが大体数十件貯まったら初期の確認としては十分なのではないかと思います。
合成データを使った評価データセットの拡充
合成データ、つまりLLMにテスト用のデータセットを拡充してもらうのも安心感を増やす意味では有効です。
何よりこれまでのやり方では最初に作ったデータセットの範囲にインプットの幅が閉じてしまいます。なので似た観点でありつつも、違う内容のインプットでテストの幅を担保することが有用です。
ただ、一方で大事なのは簡単過ぎる例を増やし過ぎないことです。 偽陽性をテストするために、理想とされる答えと真逆のことをテストデータとして用意したとて、「そら間違いと判定するやろ!!」みたいなデータになってしまうとあまりいいテストになりません。むしろそういうデータが増え過ぎて「正解率は90%を超えてるから安心だな」と偽りの安心感を抱かせてしまうかもしれません。
もちろん「さすがにこれくらいは…」と越してほしい難易度を段階的に試すのは有効だと思うので、そういう時はタグなどで難易度をつけて個別に実行できるようにするといいと思います。
参考までに最近合成データを作った例で言うと、次のように微妙に間違ったデータを作るようにGPT-4o に頼んだりしていました。パッと見では分からないがよく読むと間違えてるいい感じの例を作ってくれたりします。
def generate_slightly_wrong_output(reference_answer: str) -> str: """Generate a slightly wrong output.""" llm = ChatOpenAI(model="gpt-4o", temperature=0) output = llm.invoke( f"""Your task is to generate a wrong answer text based on the reference answer. this output is going to be used to test evaluator's ability to judge the correctness of the information. reference answer: {reference_answer} background information of the agent reply: {document} """ ) return str(output.content)
評価の評価プログラムを書く
めっちゃシンプルにリファレンスと合っているかどうかだけ確認しています。
from langsmith import EvaluationResult from langsmith.schemas import Example, Run def check_actual_score_matches_reference_score(run: Run, example: Example) -> EvaluationResult: """Evaluate if the output score of the run matches the reference score.""" actual_score = run.outputs.get("output") if run.outputs else None reference_score = example.outputs.get("output") if example.outputs else None if actual_score is None or reference_score is None: raise ValueError("actual_score or reference_score is None") score = int(actual_score) == int(reference_score) return EvaluationResult(key="matches_reference", score=score)
チューニング!
ここまで準備できたら後はスコアが高まるまでLLMシステムをいじりまくるのみです。
私の感覚的には、最近のLLMは安くて賢いので、このチューニング自体はそんなに時間がかかる印象はなく、どちらかというと「いかに評価基準をうまいこと言語化するか」の方が肝で時間がかかる気がしています。なのでプロンプトチューニングというよりは基準チューニングみたいな感覚になるかもしれません。
おわりに
以上、LLM-as-a-Judge の作り方をご紹介してきました。
ちょっと手間はかかるのですが、無事デグレを検知してくれたりすると「おお…賢い…」となんか気持ちよくなります。
先日も同僚がAgentic Workflowが含まれたシステムを改善していく際に、様々なモデルの組み合わせや、アーキテクチャーの変更(Agentic Workflow抜いたりとか)でスコアがどう変化するかを試して参考にしてくれていました。正直まだ具体的に見ていくと「ちょっと厳し過ぎるんじゃないかなぁ」とか「こういう評価観点もあるんじゃね?」とかは無限に湧いてくるのですが、一定参考となる指標ができ、安心感を持ってシステムの変更ができるようになるのは、主観でなんとなく判断していた時と比較すると大きな価値だなと感じました。
LLMによる評価を信頼できる形で作るには、多少骨は折れるものの価値はしっかりあると思います、ぜひ活用していきましょう!
最後にリンク貼っておきます。
参考文献
eugeneyan.com zenn.dev www.brainpad.co.jp arxiv.org www.sh-reya.com zenn.dev