
こんにちは。ファンと共に時代を進める、Web3スタートアップ Gaudiy の seya (@sekikazu01)と申します。
弊社では今 LLM をプロダクトに活用しているのですが、実際にユーザに提供するクオリティのものを作る・運用しようとすると様々な課題が立ちはだかってきました。
そんな数々の課題を解くために LangSmith というツールが活躍してくれた、また今後の活用・発展にもかなり期待ができるため、本記事ではそんな LangSmith について解説していきます。
LLM を使ったプロダクト開発において課題を感じている方々の参考になれば幸いです。
出てきた課題
まず LangSmith 自体の解説に入る前に、我々が直面した・ほぼ間違いなく今後するであろう課題たちをサラッとご紹介しようと思います。
大まかには次のような課題がありました。
- プロンプトがアプリケーションコード内に書かれていたので、エンジニア以外がプロンプトチューニングをする時の受け渡しが手間
- そもそもプロンプトチューニング自体がすごい手間
- 様々なプロンプトテンプレートに対するインプットの組み合わせがある
- 特に RAG で記憶を埋め込んだりするような文脈情報が多いプロンプトではデータを用意するのが大変
- プロンプトの評価基準が言語化されていない
- プロンプトはそれを持ってどんな体験をユーザに届けたいかの目的があるが、プロンプトの評価基準を最初からバシッと決めるのはおそらく不可能
- なので逐次育てていくことになるが、そのログが取れていないため、後にいじったり他の環境(使用するモデルなど)で試した際にリグレッションが起きてないか確認する術がない
これらの課題に対して LangSmith の次のような機能たちがハマりました(or まだしっかり運用に乗せられてないのでハマりそうな予感がしています)。
- プロダクトで実際に送られたプロンプトのログが取れる & それをいじれる Playground がある
- これによりエンジニアでない人も触れるようになるし、プロンプトに渡すデータもリアルなものがあるのでそれを元にいじれる
- Evaluation 機能でプロンプトのテストが書ける & データセット機能でそれに対するインプットも作れる
- Hub によってプロンプトの一元管理とバージョン管理ができる
それではこれらの機能について、より具体的に解説していこうと思います。
LangSmith の基本
まずはじめにサクッと LangSmith の超基礎的なところをお話しします。
LangSmith は、LLM アプリ開発の定番フレームワークとなった LangChain の開発元と同じところが開発している LLM アプリ開発支援サービスです。
※ LangSmith は2023/10月現在は private beta な状態なので waitlist に登録する必要があります。(ちなみに "private" とは呼んでますが、記事書いても大丈夫なことはお問合せして確認しました👍)
LangChain 本体の X でもよく新機能や Tips の紹介をしているので要チェックです。
インストールは LangChain を使っている場合、非常に簡単で、下記のように環境変数をセットするだけです。
export LANGCHAIN_TRACING_V2=true export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com export LANGCHAIN_API_KEY=<your-api-key> export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
LangChain を使っていない場合でも langsmith のパッケージがあるので、それを活用して自分で LLM の実行結果などのログを取るようにすることができます。
Organization 機能について
仕事で使っていく上で気になるのは「複数人で同じ計測を見られるか」ですが、こちらについては8月ごろに Organization 機能が追加されました。ただ、現状は Max 5人までなのでそこはご注意です。
それでは次は具体的な LangSmith の機能について解説していきます。
プロンプトのログと Playground
LangSmith の最も基礎となる機能はプロンプトのログです。 実行された結果はこのように一覧に表示されます。

詳細にいくと、こんな感じで実際に送られたプロンプトとその結果が見られます。

そして右上の Playground を押すと、そのままプロンプトや様々なパラメータをいじってチューニングすることができます。

ちなみに OpenAI API 以外にも Anthropic や Vertex などを使うこともできます。

LangSmith 導入以前はエンジニア以外がプロンプトチューニングを始めるのが手間だったのですが、今は実際に送られたプロンプトを使ってスッと Playground でいじれるようになってそのハードルが大分下がりました。
まだ「インプットを切り替えた並列実行」「繰り返し実行」などチューニングしていく上で、もう一捻り欲しいなぁと考えている機能はあるのですが、これだけでも大分嬉しいです。ありがとう LangSmith。
小ネタ: タグにプロンプト名を入れて絞り込みやすくする
プロンプトのログはそのままだと様々なログを区別するものがないため、一覧の中からチューニングしたい対象のプロンプトを目grepで見つけることになるためいささか非効率です。
これを解決するために我々は実行時にプロンプト名をタグとして入れるようにしています。実際は ChatModel を扱うところをもう少し抽象化していたりするのですが、書き方としては以下のような感じです。
llm_chain = ChatModel("model-name" ,temperature=0.7, verbose=True).chain(prompt=prompt) result = llm_chain.run(**kwargs_template, tags=["local", "test_message"])
こうしたデータを入れておくと LangSmith の UI にも次のようにタグで絞り込むためのチェックボックスが生まれます。(プロンプト以外のタグが将来的に欲しくなるかもしれないので “prompt:” みたいな prefix つけてもいいかも)

モニタリング
LangSmith では Monitor 機能が搭載されており、
- 実行数
- 成功率
- レイテンシー
- トークン消費量
などなどを確認することができます。
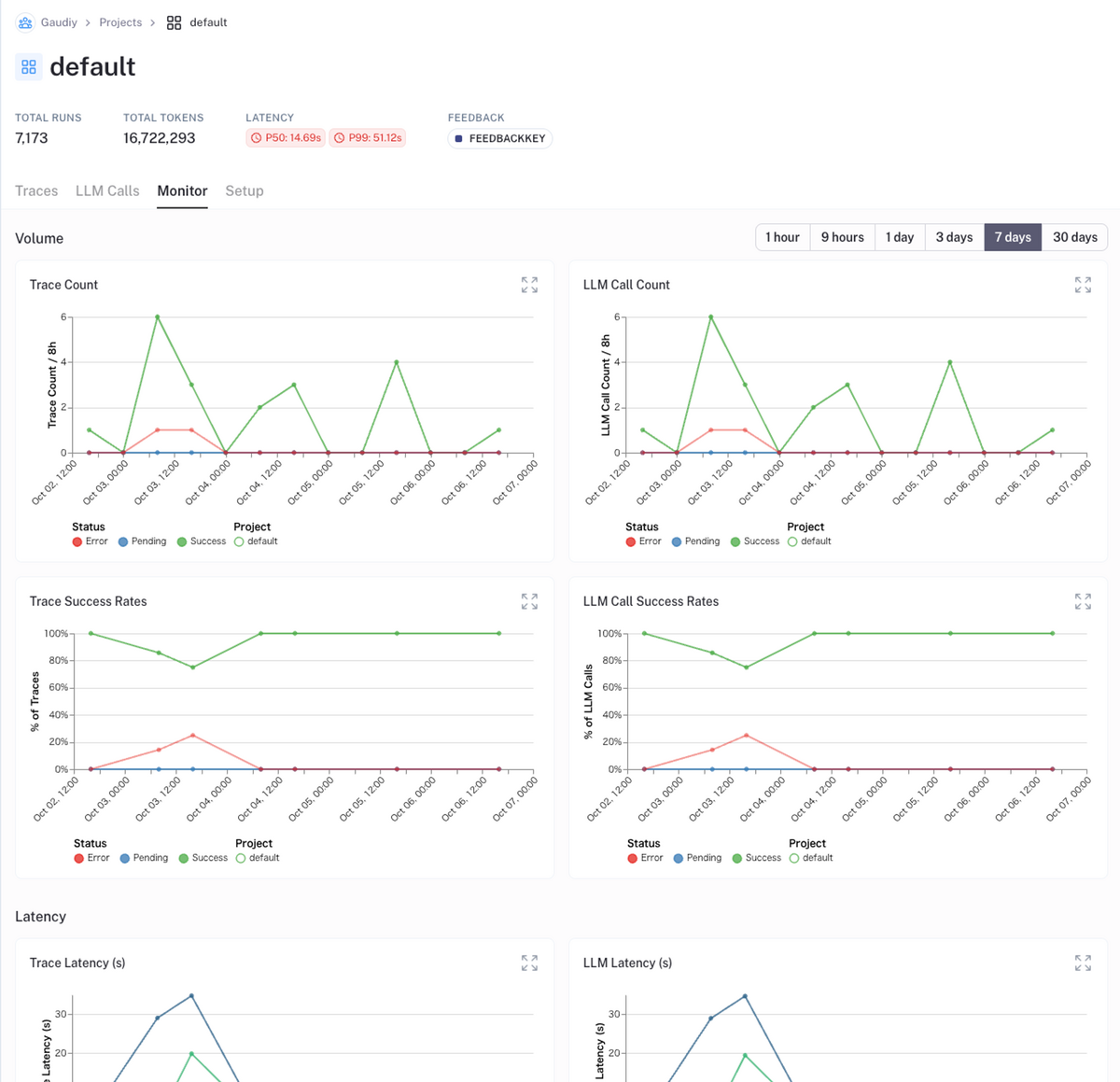
ただちょっと痒い所に手が届かない部分もあり、例として、以前気づいたらものすごい量のトークン消費をしていたことがあったのですが、その時知りたかったのが「どのプロンプトがどれくらい実行されている & トークンを消費しているのか」でした。一覧を見ていたらなんとなくアタリはつけられますが、現状 LangSmith ではこれをソートして見る方法がありません。
なるべくログを見る場所は集約したいので、この Monitor 画面でタグでフィルターできる機能ができるといいなぁとは思っていますが、現状は LangChain のコールバックでまた別のところ(我々の場合 BigQuery)に保存してクエリを書くようにしています。
詳しくは下記記事をご参照ください。
Evaluation とテスト
次に Evaluation という機能について触れていきます。
Evaluation(評価)とは呼んでいますが、目的の感覚としては単体テストを書くのに近いです。 主にはリグレッションの確認を想定しています。
例えば…
- プロンプトのトークン利用量が激しいのでプロンプト文を変えたり圧縮テクニックを使ったりする
- 使う LLM のモデルを変える
- 変数の値を変える
などなどがあり、これらの変数を変える度に都度手動で組み合わせを確認するのは中々に手間です。
そこで Evaluation 機能を活用します。 めちゃくちゃコードをかいつまむと下記のように評価基準を書いて、データセットという事前に用意したインプットを元に実行するだけです。
eval_config = RunEvalConfig(
evaluators=[
RunEvalConfig.Criteria(
{"適切な文章量": "50文字以上200文字以内に収まっているか"
" Respond Y if they are, N if they're entirely unique."}
)
]
)
result = run_on_dataset(
client=client,
dataset_name=dataset_name,
llm_or_chain_factory=create_chain,
evaluation=eval_config,
verbose=True,
)
こういった評価基準をプロンプトチューニングする過程で育てていくと後のリグレッション確認や、追加でプロンプトを調整していく時に活躍すること間違いなしでしょう。
という訳で具体的に LangSmith で Evaluation を実行するまでの道のりを紹介します。
データセットを準備する
データセットは Evaluation の文脈ではプロンプトに対するインプットとして使われます。 データセットは UI から手動でもコードからでも作ることができるのと、エライのが LangSmith メインの機能であるログからも追加することができます。
UI から追加する
New Dataset を押して Dataset を作ります。Data type は今回は key-value にしておいてください。(LLM Chain から input の JSON を入れるのが目的なため)

そして add Example から JSON 形式で追加します、実行したい対象のプロンプトテンプレートに応じて整えてください。ちなみにデータセット内のこの examples は全て同じフォーマットの JSON でないと Evaluation 実行時にエラーになるので気をつけてください。

ログから追加する
Lang Smithの素晴らしいところがログから追加できることです! ログの詳細ページから Add to Dataset をクリックしてください。

押すとこんな感じでインプットの JSON をデータセットに追加することができます。 これでテストデータを作る手間が大分削減できそうですやったぜ…。

コードから追加する
コードで追加することもでき、他のデータソースから引っ張ってきたり、それなりに量があるデータセットを作る場合にはこのやり方が重宝するでしょう。
from langsmith import Client example_inputs = [ "a rap battle between Atticus Finch and Cicero", "a rap battle between Barbie and Oppenheimer", "a Pythonic rap battle between two swallows: one European and one African", "a rap battle between Aubrey Plaza and Stephen Colbert", ] client = Client() dataset_name = "Rap Battle Dataset" dataset = client.create_dataset( dataset_name=dataset_name, description="Rap battle prompts.", ) for input_prompt in example_inputs: client.create_example( inputs={"question": input_prompt}, outputs=None, dataset_id=dataset.id, )
以下の環境変数が os.environ['LANGCHAIN_ENDPOINT'] で読めるような状態にしておいてください。
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com export LANGCHAIN_API_KEY=<your api key>
Evaluation を書く
それでは Evaluation を書いてみましょう!
冒頭に示した通りやり方としては Evaluation の基準を書いて
eval_config = RunEvalConfig(
evaluators=[
RunEvalConfig.Criteria(
{"適切な文章量": "50文字以上200文字以内に収まっているか"
" Respond Y if they are, N if they're entirely unique."}
)
]
)
データセットに対して実行するだけです。
def create_chain(): llm = ChatOpenAI(temperature=0) return LLMChain.from_string(llm, "Spit some bars about {input}.") result = run_on_dataset( client=client, dataset_name=dataset_name, llm_or_chain_factory=create_chain, evaluation=eval_config, verbose=True, )
そうするとデータセット内に評価の結果が表示されます。

そして中身のスコアのところをクリックすると、なぜその評価になったのかを確認することもできます。

※ 余談ですがこの評価にもしっかり LLM が使われているのでお金がかかることを意識しておきましょう💰
評価プロンプトはどうなっているのか
評価にも LLM が使われているのですが、我々は基準を書いているだけです。実際に LangSmith がどんなプロンプトで評価基準を活用しているのかみてみましょう
You are assessing a submitted answer on a given task or input based on a set of criteria. Here is the data: [BEGIN DATA] *** [Input]: a rap battle between Aubrey Plaza and Stephen Colbert *** [Submission]: 猫が可愛いにゃぁ *** [Criteria]: 適切な文章量: 50文字以上200文字以内に収まっているか Respond Y if they are, N if they're entirely unique. *** [END DATA] Does the submission meet the Criteria? First, write out in a step by step manner your reasoning about each criterion to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer of whether the submission meets all criteria. At the end, repeat just the letter again by itself on a new line.
Criteria 毎に改行して結果を出してというシンプルな内容ですね。
ちなみにですが、元のプロンプトは英語で与えられた文字列が日本語で大丈夫なのかと疑問に思うかもしれませんが、結論としては問題ありませんでした。おそらくですが LLM が日本語の文字列を英語として解釈してから reasoning しているように見えます。
もしかしたら日本語特有のニュアンスが失われてしまうことはあるかもしれませんが、Evaluation に影響が出るほどではないのかなと予想しています。
LangSmith のプリセット評価基準
上記では自分で評価基準を書いてましたが、LangChain もいくつかプリセットの評価基準を用意してくれているので把握しておくと楽になることがあるかもしれません。
ドキュメントには全部書いてないですが、コードから抜いてくると下記のような評価基準がありました。 自分でカスタムで作る前に同じ観点での基準があるか探してみると良さそうです。
class EvaluatorType(str, Enum): """The types of the evaluators.""" QA = "qa" """Question answering evaluator, which grades answers to questions directly using an LLM.""" COT_QA = "cot_qa" """Chain of thought question answering evaluator, which grades answers to questions using chain of thought 'reasoning'.""" CONTEXT_QA = "context_qa" """Question answering evaluator that incorporates 'context' in the response.""" PAIRWISE_STRING = "pairwise_string" """The pairwise string evaluator, which predicts the preferred prediction from between two models.""" LABELED_PAIRWISE_STRING = "labeled_pairwise_string" """The labeled pairwise string evaluator, which predicts the preferred prediction from between two models based on a ground truth reference label.""" AGENT_TRAJECTORY = "trajectory" """The agent trajectory evaluator, which grades the agent's intermediate steps.""" CRITERIA = "criteria" """The criteria evaluator, which evaluates a model based on a custom set of criteria without any reference labels.""" LABELED_CRITERIA = "labeled_criteria" """The labeled criteria evaluator, which evaluates a model based on a custom set of criteria, with a reference label.""" STRING_DISTANCE = "string_distance" """Compare predictions to a reference answer using string edit distances.""" PAIRWISE_STRING_DISTANCE = "pairwise_string_distance" """Compare predictions based on string edit distances.""" EMBEDDING_DISTANCE = "embedding_distance" """Compare a prediction to a reference label using embedding distance.""" PAIRWISE_EMBEDDING_DISTANCE = "pairwise_embedding_distance" """Compare two predictions using embedding distance.""" JSON_VALIDITY = "json_validity" """Check if a prediction is valid JSON.""" JSON_EQUALITY = "json_equality" """Check if a prediction is equal to a reference JSON."""
run_on_dataset の返り値
こんな感じの結果サマリっぽいものが返ってくるので、それを元に CI で判定とかもできるかもしれません。
{ "project_name":"0f5fcfffcd824b5c9ae533e9b9b27d86-LLMChain", "results":{ "83a72ad6-0929-4456-bcea-a3966ce01318":{ "output":{ "input":"a rap battle between Aubrey Plaza and Stephen Colbert", "text":"猫が可愛いにゃぁ" }, "feedback":[ "Feedback(id=UUID(""bd7ccd82-af71-4f39-a5ac-f5ef4ca53ac4"")", created_at=datetime.datetime(2023, 9, 6, 59, 36, 813970), modified_at=datetime.datetime(2023, 9, 6, 59, 36, 813970), "run_id=UUID(""62cd7d98-10e3-4a40-95d6-1bd14215b27f"")", "key=""適切な文章量", score=0.0, value=0.0, "comment=""The criteria is asking if the submission is between 50 and 200 characters long. The submission \"猫が可愛いにゃぁ\" is only 9 characters long. Therefore, it does not meet the criteria.\n\nN", "correction=None", "feedback_source=FeedbackSourceBase(type=""model", "metadata="{ "__run":{ "run_id":"780943ca-496a-4ba1-8bc0-2de00bdb2d1e" } }"))" ] } } }
LangSmith の Cookbook の中にも pytest を使ったサンプルコードがあるのでこちらもご参考ください。
小ネタ: RAG を使った評価
先ほど注意点としてサラッと書きましたが、この Evaluation は LLM を使って行われているため時間もかかるしお金もかかります💰
そこで最近ちょっと話題だったのが Embedding を使った評価です。この手法では Embedding で事前に用意した想定回答との類似度を見ることによって LLM の遅さと API 代の高さをカバーしています。
評価手法も色々策定されていってるので知見を育てていきたいですね。
Hub によるプロンプトの管理
こちらはまだ運用で試せていないのですが、結構個人的には期待している機能です。
LangSmith の中に Hub という機能があり、ざっくり言うとプロンプトの共有サイトです。色んな人が投稿しているプロンプトを見て学ぶことができます。

が、これはプライベートなプロンプト管理ツールとしても優秀な予感がしています…!というのも以下の機能を備えているからです。
プロンプトは private にもできる
上記は公開されたプロンプトたちですが、Organization 以外の人が見られない private な状態にすることができます。

hub.pull でプログラマブルにアップロードしたプロンプトを引っ張ってこれる
下記のコードだけで Hub で作成したプロンプトを読み込むことができます。
from langchain import hub obj = hub.pull("gaudiy/some-prompt")
ちなみに LANGCHAIN_API_KEY がない場合ちゃんと読み込めないことを確認したので、プライベートにしたプロンプトもちゃんと認証されています。
これを実行すると、上記の obj の中には次のようなデータが返ってきます。一通りのプロンプトのテンプレートやインプットの定義が取得できるので、これをコードにもバッチリ反映できます。
input_variables = ['post_content', 'feedback'] output_parser = None partial_variables = {} messages = [ SystemMessagePromptTemplate( prompt=PromptTemplate( input_variables=[], output_parser=None, partial_variables={}, template='あなたはプロのプロです。', template_format='f-string', validate_template=True ), additional_kwargs={} ), HumanMessagePromptTemplate( prompt=PromptTemplate( input_variables=['key', 'value'], output_parser=None, partial_variables={}, template=( 'こちらはホゲホゲ\n' '{key}\n\n' 'ホゲータ\n' '{value}\n\n' '上記のフィードバックを元に投稿の内容を修正してください。' ), template_format='f-string', validate_template=True ), additional_kwargs={} ) ]
コミットログと共にバージョン管理をすることができる
コミットのタイトルや変更理由を書く場所がないのがちょっと惜しいポイントではありますが、バージョン管理をすることができます。

これらの機能と共にこの Hub をプロンプトの Single source of Truth として扱えないかなぁと画策しています。具体的には下図のように Hub で変更があったら CI で検知してコードに反映し、都度 Hub にリクエストを送らずとも実行できるようにならんかなと。
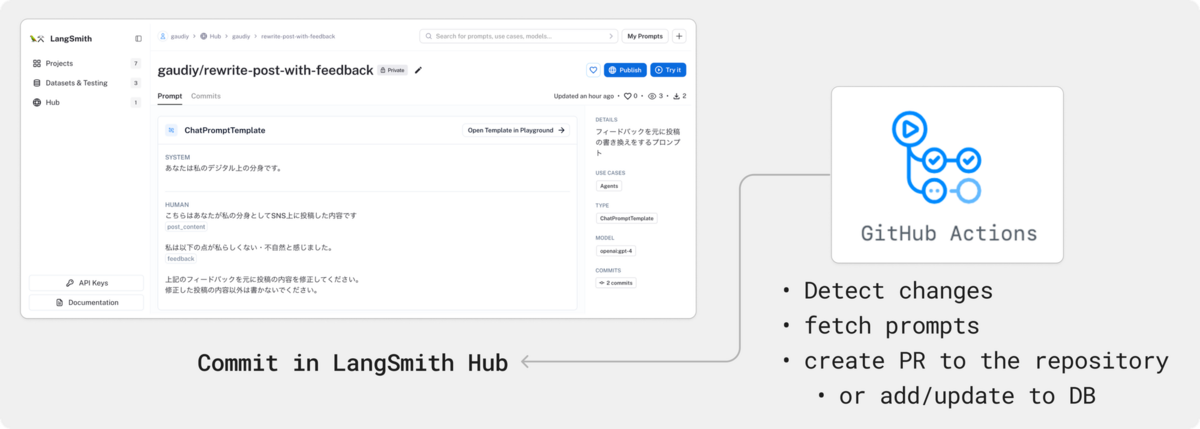
ですが、今の所以下の機能が足りておらず、ゴリ押しできなくはないのですが今後に期待かなぁという印象です。
- 階層やタグをつけることができない
- プロンプトが大量に増えてくるとドメインに応じて分割して管理したくなってくる
- Oranization のもの全部とってくるみたいなことができない
- commit した時に変更検知できない
- Webhook とかできると嬉しいかも
データの取り扱いについて
最後に、技術的な話ではないのですが、プロンプトのデータを LangChain のサーバに送ることもあり、内容によってはそもそも送って良いのかだったり利用規約の改変の必要があるかが議題に上がったので、そこで法務の方に相談して調べていただいた内容を記します。
結論から申し上げると
LangSmithでの個人データの処理については、規約・プライバシーポリシーを踏まえると、「個人データの取り扱い」ではないと整理できるので、いわゆるクラウドでの情報の取り扱いと同じく、同意は不要と考えて問題なさそうです(弁護士確認済み)
とのことでした。
LangSmith の利用規約とセキュリティーポリシーのリンクは下記の通りです。
https://smith.langchain.com/terms-of-service.pdf https://smith.langchain.com/data-security-policy.pdf
利用規約の 4.1 に「LangChain agrees that it will not use Customer Data to develop or improve its products and services」と「個人データを取り扱わない旨」が定められており、また、4.2の「(i) ensure the security and integrity of Customer Data (ii) protect against threats or hazards to the security or integrity of Customer Data; and (iii) prevent unauthorized access to Customer Data」と定められているため「適切にアクセス制御」も行われていると考えられる、とのことでした!
もちろんプロンプトの用途によっては、法律的にはOKでも世間的・倫理的にはアウトみたいなことはあり得るので都度判断が必要ですが、ひとまず規約に明示的にこの LangSmith のための同意を得る対応は必要なさそうです。
おわりに
以上、LangSmith の機能の解説と我々のチームで発生している課題の解決への希望について触れていきました。
実は似たような、いわゆる LLMOps と呼ばれるツールは今まさに群雄割拠で色んなツールが出てきているのですが、セットアップの簡単さからもわかる通り、 LangSmith の優位性は「LangChain という LLM アプリ開発のデファクトになりつつあるツールとの連携がすごい」ことにあるのかなと考えています。 トラッキング始めるまでの準備も環境変数を仕込むだけですし、ログも LangChain の Chain の種類に応じていい感じに整えて取得してくれます。
ある意味ではロックインのリスクとも取れるかもしれないのですが、LangChain をプロダクト開発に活用されている方はトライしてみるのもいいのではないでしょうか?
最後に、Gaudiy では現在 LLM をかなり踏み込んで活用して新しいエンタメ体験を鋭意開発中です!もしご興味持っていただければ一緒に働きましょう💪
https://herp.careers/v1/gaudiy/FAqLGhW5HFr5herp.careers
まずはカジュアル面談で「いや LLM 開発実際はね〜…」みたいなところから雑談するのでも大丈夫です、お待ちしております。
https://recruit.gaudiy.com/9b513345d630418799bdbb219acc7063recruit.gaudiy.com
それでは!!!👋