
こんにちは。ファンと共に時代を進める、Web3スタートアップ Gaudiy でソフトウェアエンジニアをしている ryio1010です。
私は弊社が提供するファンコミュニティプラットフォーム「Gaudiy Fanlink」の開発において、フィーチャーチームの一員として、主にバックエンド開発を担当しています。
バックエンドのアーキテクチャにはマイクロサービスを採用していますが、会社のフェーズ的に試行錯誤の段階であることや、それに伴うチーム体制の変更がよく起きていることもあり、新しいマイクロサービスの立ち上げも頻繁に行われています。
私自身もこれまでの業務で2〜3つの新しいマイクロサービスを立ち上げる経験をしてきました。
今回は、これらのマイクロサービスの立ち上げと運用の経験から、特に立ち上げフェーズにフォーカスし、改善を行った事例をご紹介したいと思います。
- 1. マイクロサービスの概要とGaudiyのシステム構成について
- 2. 既存の新規構築手順と課題感
- 3. 具体的なアプローチ方法と効果
- 4. おまけ(CloudRun→Kubernetes移行について)
- 5. おわりに
1. マイクロサービスの概要とGaudiyのシステム構成について
本記事をお読みの皆さんにとって、マイクロサービスの概念はすでにご存知の内容かもしれません。しかし、後続の内容をより深く理解していただくために、まずはマイクロサービスの基本的な概念と、Gaudiyにおけるシステム構成の現状を簡潔にご説明します。
1-1. マイクロサービスとは?
マイクロサービスは、大規模なアプリケーションを小規模かつ独立したサービス群として構築する設計手法です。このアーキテクチャスタイルでは、各マイクロサービスが特定の機能やビジネス要件に特化し、独立して開発、デプロイ、運用されます。
例えば、Gaudiyでは、ユーザー関連の処理を担う「user-service」、投稿関連の処理を担う「post-service」などが存在します。
マイクロサービスはそれぞれ独立しているため、Go、Kotlin、TypeScriptなど、異なるプログラミング言語での開発も可能です。
実際にGaudiyでは、これらの言語を使用したマイクロサービスを運用しています。
主なメリットは以下の通りです:
- 開発とデプロイメントの迅速化: 各マイクロサービスは独立して開発・デプロイできるため、迅速な更新が可能。
- 耐障害性の向上: サービス間が疎結合になるので一つのサービスに障害が発生しても、他のサービスには影響が少ない。
- 複数技術スタックの利用: 異なるサービスで異なる技術スタックを採用できる。
一方でデメリットも存在するため、考慮に入れておく必要があります。
- 通信の複雑さ: サービス間の通信が多く、複雑になる傾向がある。
- データ管理の難しさ: 分散したサービス間でのデータ一貫性の維持が課題。
- 運用コストの増加: 個別サービスの監視・管理には追加の労力とリソースが必要。
多くのメリットがあるマイクロサービスですが、上記のようなデメリットもあります。 この記事では、マイクロサービスの運用におけるコスト増加の部分、特に新規マイクロサービスの立ち上げコスト削減に焦点を当てています。
1-2. Gaudiyのシステム構成
現在のシステム構成は下記のようになっています。
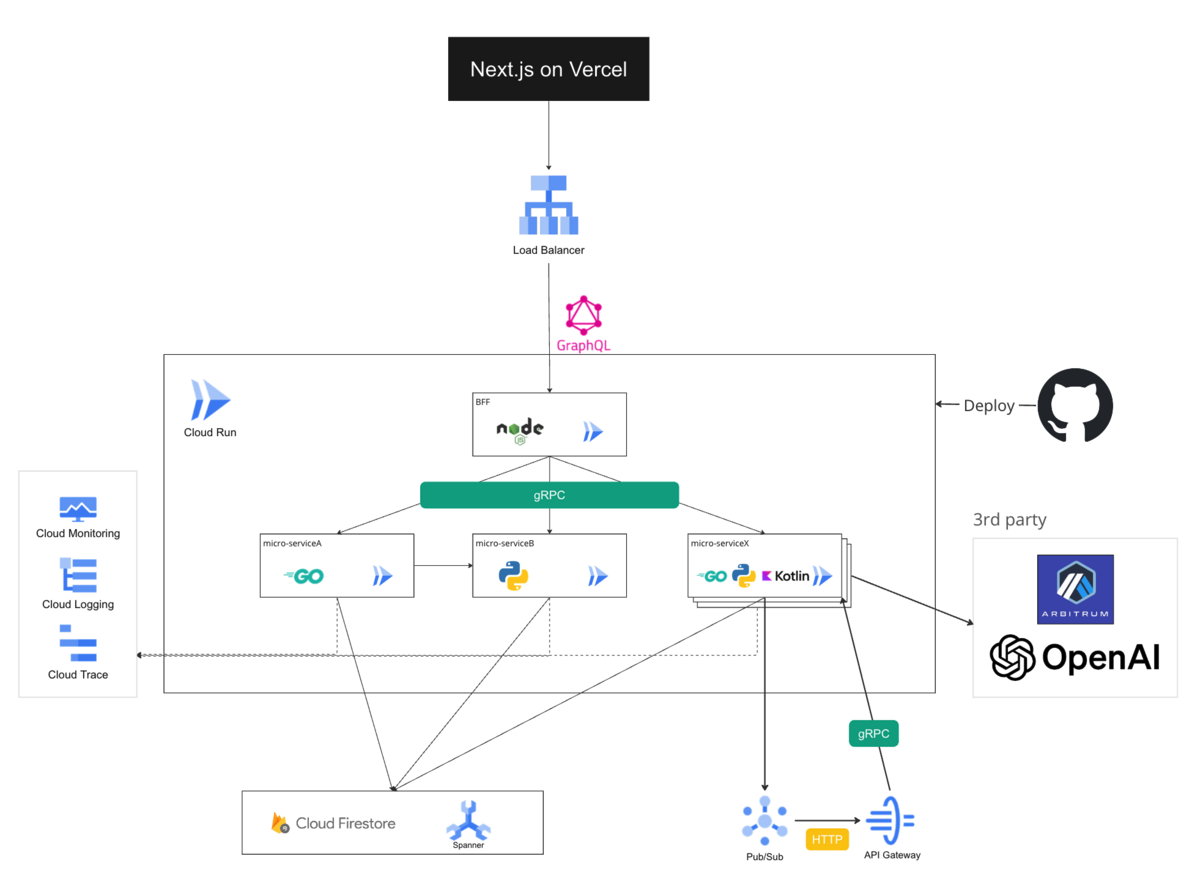
フロントエンドではReact(Next.js)とTypeScriptを用い、BFFとしてApollo ServerとTypeScriptを採用しています。バックエンドではGoとKotlin・Pythonを使用したマイクロサービス群を構築しています。 これらの技術スタックを基に、ブロックチェーン技術やAI・LLM(Large Language Models)技術を取り入れながら、当社のプロダクト「Fanlink」の開発を進めています。
バックエンドに焦点を当てると、ホスティング環境としてGoogle CloudのGKE(Google Kubernetes Engine)を使用しています。現在、20近くのマイクロサービスをGKE上で運用しています。
2. 既存の新規構築手順と課題感
2-1. これまでのマイクロサービス構築手順
まず、弊社で新規マイクロサービスを立ち上げるために必要な要素と、従来の構築方法についてご説明します。
新規マイクロサービスの立ち上げには、大きく分けて以下の3種類が必要です。
- マイクロサービス用のgRPCサーバーのコードベース(Go)
- GCP環境でホストするためのGCPリソースを作成するTerraformファイル群
- 各環境へのデプロイなどを担うCI/CDやDBマイグレーションを行うGitHub Actions用のyamlファイル群
2-1-1. gRPCサーバー用のコードベース(go)
まずマイクロサービスのサーバー本体となるコードベースについては、一部はKotlinを採用していますが、新規サービスは基本的にGoを使用しています。
Gaudiyにはecho-serviceという、いわゆる新規マイクロサービスの元になるコードベースがあります。
このテンプレートには、ログクライアントの設定、DBクライアントの設定、サーバーの起動など、マイクロサービスに必要な基本機能がGoで書かれています。
これまではこのecho-serviceをコピーする形で新しいマイクロサービスのコードベースを作成していました。コピーしていく中で、コードベースの中の名前を新しく作成するマイクロサービスのドメインに合わせるように手作業で修正していくという形でした。
手作業で修正する必要があり、その量もそれなりになるため、細心の注意を払っていたとしてもヒューマンエラーが発生したり、そもそもecho-serviceからの新規サービス作成が初めてな人も多いので必要以上に時間がかかってしまうことも少なくない状況でした。
2-1-2. terraformファイル
GCP環境でマイクロサービスを動作させるためには、Service AccountやSpanner InstanceなどのGCPリソースが必要です。
これらのインフラ管理はTerraformを用いて行っており、既存のファイルに新規マイクロサービスのリソースを追加する必要があります。
この作業に関しては手順書があるため、他の作業に比べると比較的スムーズに作業できていました。
2-1-3. cicd用yamlファイル
各マイクロサービスには下記のためのgithub actions用のyamlファイルがあります。
- 各環境へdeploy用
- SpannerDBのマイグレーション用
- 各PRの確認用(ユニットテスト実行・lint実行など)
これらに関しては手順書もなく、これまで新規構築したことのあるメンバーに逐一どのファイルが必要かを確認して手動で作成している状況でした。
ファイルの追加漏れなどヒューマンエラーも発生しやすい状況となっており、実際私もDBマイグレーション用のファイル追加がもれており、DBのマイグレーションが実行されず追加し直すといった手戻りが発生してしまった経験がありました。
2-2. 課題感
マイクロサービスは上記でお伝えした利点があり採用しているのですが、会社のフェーズ的にも試行錯誤をしていく中で、実績値で平均すると2-3ヶ月に1回くらいのペースで新しいマイクロサービスを立ち上げていました。
私は新規マイクロサービスの構築に多く関わる機会があり、初めて構築を行う中で以下の課題があると個人的に感じていました。
- 初期構築手順書はあるものの、十分に更新されておらず有識者に確認する必要があり開発の手が止まってしまう
- 手順書には書かれていない暗黙知があり、チームメンバーによっては暗黙知を持っておらず新規構築したもののなぜがうまく動かないといったことが起こりうる
- 基本的に手作業でテンプレートとなるディレクトリをコピーする形でコードベースを作るのでタイポなどのヒューマンエラーが発生し、作業が手戻りしてしまう
- そもそも手順が多く手作業が大変
上記の状況の中で、実際に新規マイクロサービス基盤の構築が完了しコア機能の開発に入るまでに1-2人日くらい工数がかかっているため、少なからず開発スピードを鈍化させる原因になっていることは明らかでした。
また基本的にどんなマイクロサービスを立ち上げるとしても、そのマイクロサービスが扱うドメインの名称が違うだけで新規立ち上げの作業自体は定型的なものであるため、十分に自動化できうるものでした。
3. 具体的なアプローチ方法と効果
3-1. アプローチ方法
先にご紹介した新規マイクロサービス構築に必要な3種類の作業のうち、Terraformに関しては手順書通りの追記で問題なく、大きく工数を要していなかったため、GoサーバーのコードベースとGitHub Actions用のyaml群の生成を自動化の対象としました。
詳しい実装については割愛しますが、おおまかに下記のような処理を実装している「gauctl」という名前のCLIを作成しています。
- GitHubのリポジトリからecho-serviceをクローン(tarファイル)
- 取得したtarを解凍
- 変更が必要な箇所を新規マイクロサービスのドメイン名で置換
- GitHub Actions用のyamlのテンプレートを基に、新規マイクロサービス用のyamlを生成(Go言語のテンプレート機能を利用)
- 適切なディレクトリに生成ファイルを出力
3-2. 利用した技術について
利用した技術スタックは以下の通りです。
- Go言語
- Cobra(GoのCLI アプリケーションフレームワーク)
Go言語はCLIツールの作成に適しているだけでなく、Gaudiyではバックエンドに広く採用されており、多くのエンジニアが読み書きできるため、将来的なメンテナンスの観点からも採用することにしました。
またCobraはGo製のCLIフレームワークで、容易にコマンド生成やフラグ処理などを直感的なAPIで実装できるため、開発の効率やメンテナンスが容易になるという点から採用しました。
ここではより具体的な実装イメージを持っていただくためにも、yamlの生成で利用したGo言語のテンプレート機能とCLIアプリケーションフレームワークとして利用したCobraについて簡単な使い方をご紹介できればと思います。
3-2-1. Go言語のテンプレート
今回yamlの生成にはGo言語のテンプレート機能を利用しました。
この機能を使うことで動的なデータ(今回の場合は新規マイクロサービスのドメイン名)を静的テキストファイルに組み込むことができ、”text/template”パッケージから利用できます。
ディレクトリ構成は下記の感じです。(一部抜粋)
├── transform
│ └── templates
│ └── sample1.yaml
│ └── sample2.yaml
│ └── embed.go // yamlファイルをbyte配列で読み込む処理を記載
│ └── transform.go // yamlの中身を変換する処理
yamlファイルの中身で変換したい部分には「{{ . }}」と記載します。
(この部分がtemplateの機能によって変換されます。)
// transform/templates/sample1.yaml
name: Check PR for {{ . }}-service
on:
push:
branches:
- "main"
paths:
- "{{ . }}-service/**"
pull_request:
paths:
- "{{ . }}-service/**"
まずembed.goで”embed”パッケージを利用して”templates内のファイルをbyte配列で読み込んでいます。そしてそれをTransform関数の引数として渡しています。
// transform/transform.go
// contentにyamlファイルのbyte配列を、replacedStrには変換したいドメイン名が入る
func Transform(content []byte, replacedStr string) ([]byte, error) {
// New関数でテンプレートを作成して、Parse関数で文字列を解析し、テンプレート定義に追加する
t, err := template.New("yaml").Parse(string(content))
if err != nil {
return nil, fmt.Errorf("failed to parse: %w", err)
}
var buf bytes.Buffer
// Execute関数で、テンプレートの内容を変更し、bufに格納する
if err = t.Execute(&buf, replacedStr); err != nil {
return nil, fmt.Errorf("failed to execute: %w", err)
}
return buf.Bytes(), nil
}
上記のTransformが実行されると、sample1.yamlは下記のようになり、それを指定したディレクトリに出力しています。
(replacedStrにfooを指定した場合)
// transform/templates/sample1.yaml
name: Check PR for foo-service
on:
push:
branches:
- "main"
paths:
- "foo-service/**"
pull_request:
paths:
- "foo-service/**"
このようにtemplate機能を使うことで動的なコンテンツを簡単に作成することができます。
3-2-2. Cobra
CLIのディレクトリ構成は下記の感じです。(一部抜粋)
(cobraのコマンドをインストールして自動生成もできます。)
$ go install github.com/spf13/cobra-cli@latest
$ cobra-cli init
├── cmd
│ └── create.go
│ └── root.go
├── main.go
サブコマンドもコマンドでファイル生成できます。
(↓のコマンドを実行すると、cmd下にcreate.goが生成されます。)
$ cobra-cli add create
Cobraでのサブコマンドの実装はCommandというStructのフィールドに値を定義していく形で作成します。
基本的なフィールドの説明は下記になります。
- Use: コマンド名とその使用方法(引数など)を定義
- Short**:** コマンドの短い説明
- Args**:** コマンドに渡された引数を検証する関数を定義
- RunE: エラーを返却できる、コマンドが実行された際に呼び出される関数の定義
上記以外にも色々と設定できる項目はあるものの、基本的にRunEにサブコマンドが実行された時に実行したい処理を書くことでCLIを実装することができるようになっています。
// cmd/create.go
package cmd
import (
"fmt"
"github.com/spf13/cobra"
)
var (
createExample = `
* Create new micro-service from template
`
createCmd = &cobra.Command{
Use: "create [domain_name arg]",
Short: "Create new micro-service from template",
Example: createExample,
Args: func(cmd *cobra.Command, args []string) error {
// 引数に関する処理(引数の検証など)をここに記述できる
if len(args) != 1 {
return fmt.Errorf("requires 1 arg(s), received %d", len(args))
}
return nil
},
RunE: func(cmd *cobra.Command, args []string) error {
// 以下にコマンドが実行された時に実行したい具体的な処理を記述
return nil
},
}
)
func init() {
rootCmd.AddCommand(createCmd)
}
CobraはKubernetesやDockerなどでも採用されているとのことで筆者も初めて使用してみましたが、直感的で分かりやすく、素早く軽量のCLIを作成するツールとして優れていると感じました。
3-3. 実際の効果
CLIをリリースしてから、既に4つの新規マイクロサービスが立ち上がっており、全てこのCLIを使用いただいています。
以前は1-2日かかっていた環境構築作業が、定型作業を自動化することができたため、現在ではおよそ半日で完了するようになりました。
手順は以下のように変わりました。 特に時間を要していたecho-serviceのコピーとドメイン名の置換作業、およびGitHub Actions用のyamlファイルの作成作業が、コマンド一つで完了できるようになりました。
3-3-1. これまで
- echo-serviceをコピー
- echo-serviceのドメイン部分を新規マイクロサービスの名称に置換し、Goサーバーのコードベースを作成(ここに多くの工数がかかっていた)
- Terraformファイルに必要なリソースを追加
- GitHub Actions用のyamlファイル群を追加(ここも手順書がなく、工数がかかっていた)
- PRを出す
- レビューし、mainブランチへマージ
- CI/CDにより新規マイクロサービスの環境が構築される
3-3-2. CLI導入後
- CLIを実行(マイクロサービスのコードベースとGitHub Actions用のファイル群を生成)
- 実際のコマンド例: foo-serviceを作りたい場合
- gauctl create foo
- 実際のコマンド例: foo-serviceを作りたい場合
- Terraformファイルに必要なリソースを追加
- PRを出す
- レビュー、mainブランチへマージ
- CI/CDにより新規マイクロサービスの環境が構築される
主にヒューマンエラーや経験不足(暗黙知だった部分)が原因で発生していた手戻りや、定型的な作業を自動化することで、工数を大幅に削減できたのかなと思います。
4. おまけ(CloudRun→Kubernetes移行について)
少しおまけ的な話にはなりますが、当時、マイクロサービスのホスティングはCloud Runを利用していました。そのため、初回リリース時にはCloud Runで動作するコードベースを自動生成するCLIを作成していました。
その後、全社的にCloud RunからKubernetesへのホスティング基盤の移行が行われました。この移行は、横断的なチームであるenableチームによって進められました。 それに伴い、CLIもKubernetesで使用できるように機能拡張が必要となりました。
詳しい話は別の機会に書かせていただければと思いますが、Cloud Runとは違いKubernetesで動作させるためには、deployment.yamlやservice.yamlなどの設定ファイルが必要になります。 したがってKubernetesに対応するために、これらの設定ファイルを生成するコマンドを追加し、必要なファイルの自動生成が可能になりました。
Kubernetesへの移行経緯や移行方法の詳細は、以下の記事で詳しく書かれています。興味のある方はぜひご覧いただけるとうれしいです!
5. おわりに
この記事では、マイクロサービスを運用する中でも特に新規立ち上げフェーズにフォーカスし、改善を行った事例についてお伝えさせていただきました。
改善を行う際のコストと効果を比較して改善するべきかを熟考することは重要ですが、定型的な作業の自動化は、ヒューマンエラーによる手戻りの防止や開発スピードの改善に寄与できると思うので、積極的に改善して良い部分になるかなと思います。
また、定型的な作業は自分の所属するチーム内だけではなく、他のチームも同様の課題を抱えがちです。そのため、開発組織全体の開発スピード向上に寄与しやすい部分なのではないかと個人的には感じています。
Gaudiyでは、課題に直面した際、本人が主体的に積極的に解決に取り組む文化があります。これは一人で行うのではなく、周囲を巻き込みながら(アドバイスをもらったり、改善方針のすり合わせなどで相談に乗ってもらえる)課題解決を進めていけるので気軽に改善活動に取り組めると感じています。
今後もフィーチャーチームに在籍しながら、横断的に解決できる課題を見つけ、開発スピードの向上に寄与していければと思います〜!
今回の記事が皆さんの参考になれば幸いです。
Gaudiyでは、一緒に働くエンジニアを積極的に募集しています。当社の技術や開発スタイルに興味を持った方は、選考前のカジュアル面談も可能ですので、ぜひ採用ページからお気軽にご応募ください!