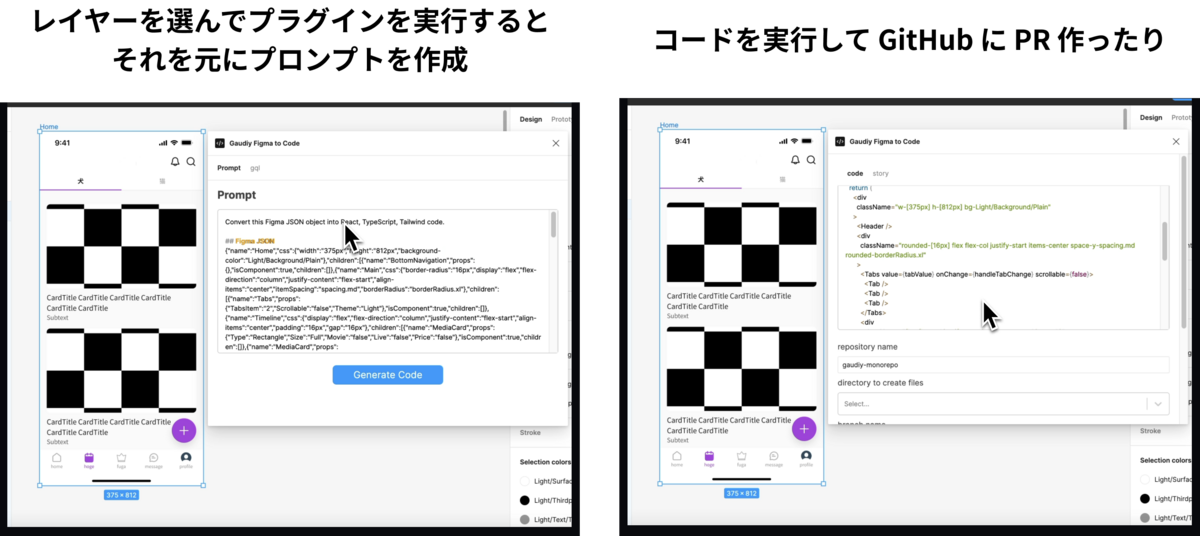
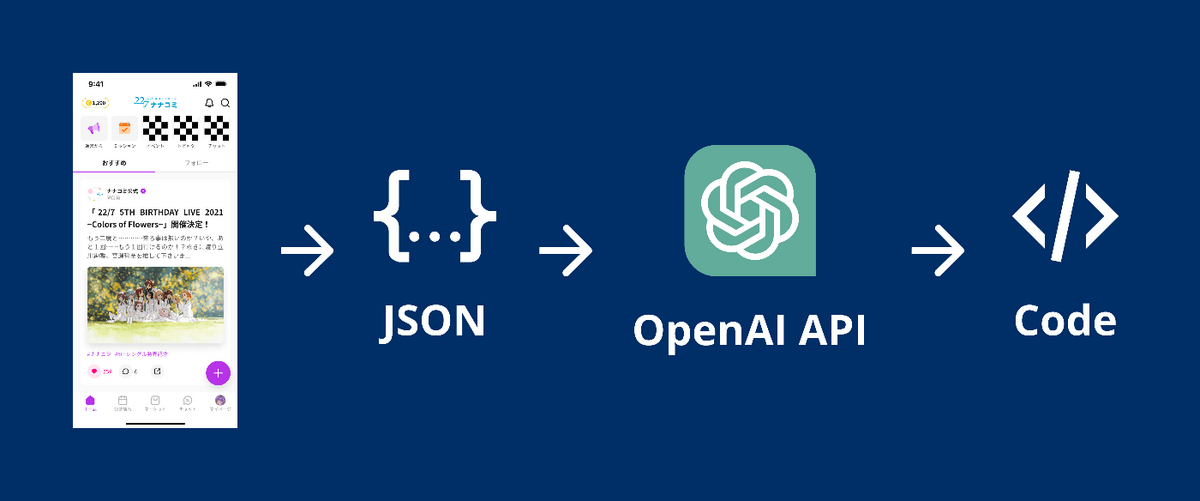
Convert this Figma JSONobject into React, TypeScript, Tailwind code.
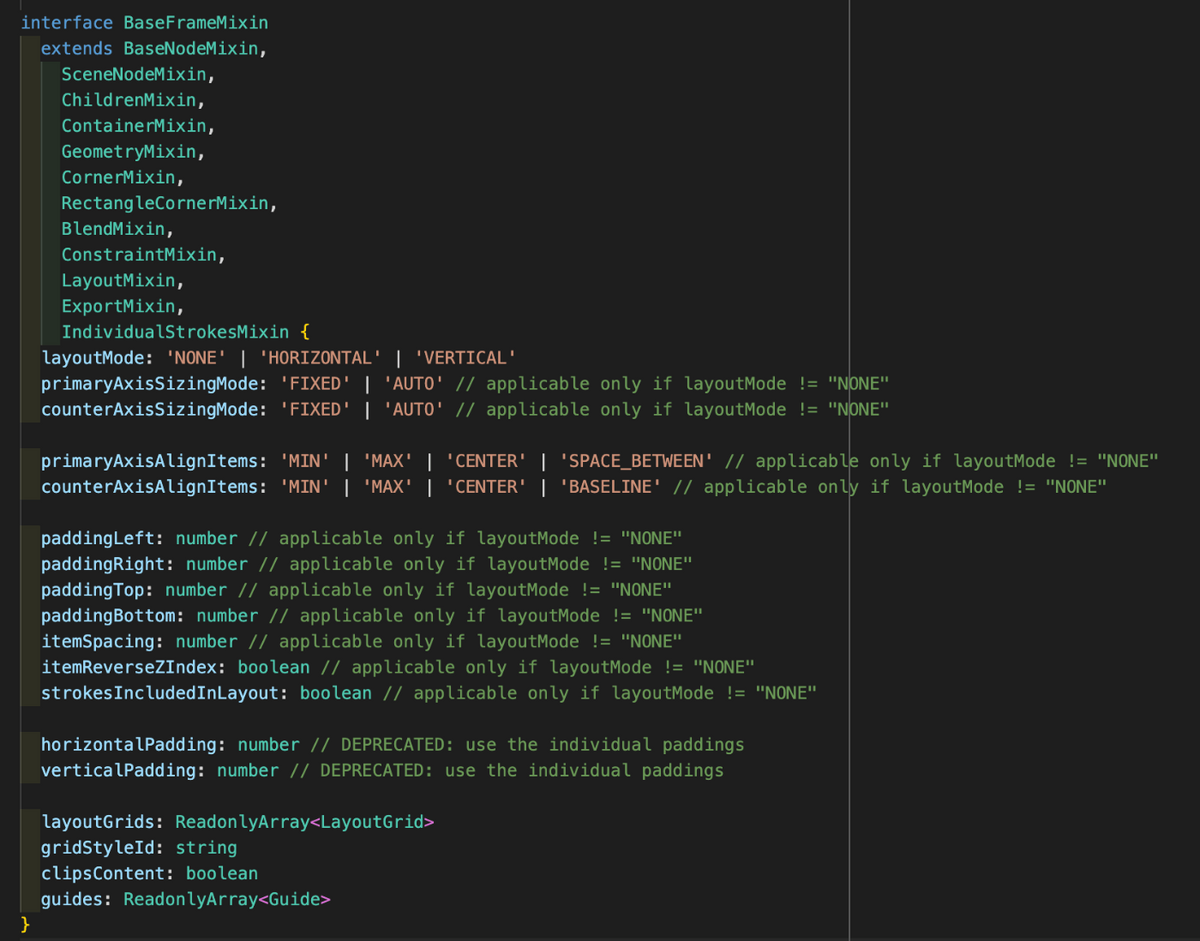
## Figma JSON{ここにさっきの Figma の JSON を貼る}
## constraints
- component does not take any props
- do not omit any details in JSX
- Do not write anything besides code
- import components from @/components directory
- if a layer contains more than 1 same name child layers, define it with ul tag and create array of appropriate dummy data within React component and use map method to render in JSX
- use export rather than defaultexport
- if Props summaries are provided for the components used in JSON, write props that are required in code props and omit props that only exist in Figma JSON
exportconst buildPromptForPropsSummary =(
componentName: string,
codeString: string)=>{return`Write Summaries of Props of ${componentName} component in the following code## Code\`\`\`tsx${codeString}\`\`\`## constraints- start with a sentence "{ComponentName} component:"- write list of props with TS type`;};
ちなみにプロンプトでは JSX 部分だけ吐き出してもらう部分はこんな感じで指定しています。Write only JSX だけだと関数宣言の部分も含んじゃったので、例を入れると安定して出力してくれるようになりました。
- Write only JSX
for instance if the result code is like below:
\`\`\`
import { Hoge } from "hoge";
export const ExampleComponent = () => {
return <div>....</div>
}
\`\`\`
Then output only
\`\`\`
<div>....</div>
\`\`\``;
};
既存のコードを渡すと差分だけ書いてもらう
これはシンプルにページの既存コードを渡して do not change previous code と指定すれば変わった部分だけ追加して出力してくれます。かしこい!
function setFigmaTokens(node: SceneNode, properties: CSSData){const tokenKeys = node
.getSharedPluginDataKeys('tokens')// Omit "version" and "hash" because they are not tokens
.filter((key)=> key !=='version'&& key !=='hash');
tokenKeys.forEach((key)=>{const value = node.getSharedPluginData('tokens', key);if(value){// remove css that's represented by tokenif(key ==='itemSpacing'){delete properties['gap'];}
properties[key]= value.replaceAll('"','');}});}
- if string value other than hex or rgb() format is specified for color property, it is design token vairable. it is defined with the name in kebab-case in tailwind.config.js
- if "typography" property is specified, it is defined in tailwind config as typography token that has multiple properties such as font-family, font-size, font-weight, line-height
exportconst buildPromptForStorybook =(
codeString: string,
componentName: string)=>{return`Write storybook for the following component in Component Story Format (CSF).\`\`\`tsx${codeString}\`\`\`## constraints- Do not write anything besides storybook code- import component from the same directory- do not have to write stories for componnents used in ${componentName}`;};
PR を作るところまでサポート
コードが出力されても、そこから
ブランチを切る
ファイルを作成
そこにコピペ
という手間がまだ存在します。せっかくならそんな手間も減らしたい...。という訳で GitHub API を使って PR を作るところまでサポートしています。
exportconst buildPromptForSuggestingBranchNameCommitMessagePrTitle =(
codeString: string)=>{return`Suggest- branch name- commit message- PR title- component namefor the following code\`\`\`tsx${codeString}\`\`\`## constraintsout put as JSON in following property names, do not include new line since this string is going to be parsed with JSON.parse{ "branchName": "branch name", "commitMessage": "commit message", "prTitle": "PR title", "componentName": "component name" }`;};
例えばですが、現状ではデザイナーがスクラッチで(コンポーネントやデザインシステムのルールに則ったりはあると思いますが)デザインを作っていってると思いますが、もしかしたら今後は作りたい仕様・ユースケースと既にあるデザインをインプットにしたら AI がデザイン案を出してくれて、それをちょっとチューニングして実装するUIデザインのプロセスが訪れるかもしれません。
// Application.ktfun Application.module() {
...
// Env is original config class.val env = Env.of(environment)
val openTelemetry = setOpenTelemetry(env)
install(Koin) {
module(
org.koin.dsl.module(createdAtStart = true) {
single { openTelemetry }
single { SampleService(get(), get()) } // openTelemetry利用クラス
}
)
}
...
val sampleService by inject<SampleService>()
routing {
sampleRouting(sampleService)
}
}
2-1-4. Jaeger起動&Application起動&エンドポイント叩く
$ docker compose up
$ ./gradlew runShadow
{"time":"2022-12-14T17:43:01.261Z","message":"Autoreload is disabled because the development mode is off.","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T17:43:04.317Z","message":"Application started in 3.156 seconds.","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T17:43:04.323Z","message":"Application started: io.ktor.server.application.Application@2eda4eeb","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T17:43:04.588Z","message":"Responding at http://0.0.0.0:8080","logger_name":"Application","thread_name":"DefaultDispatcher-worker-1","severity":"INFO"}
$ curl http://localhost:8080/sample
2022-12-15T02:46:40.909022
// SampleService.ktimport io.opentelemetry.instrumentation.annotations.WithSpan
class SampleService(privateval repository: SampleRepository) {
@WithSpanfun execute() {
val data = repository.get()
println(data)
}
}
2-2-4. Jaeger起動&Application起動&エンドポイント叩く
Jaegerのdockerファイル用意は手動計装と同じなので割愛します。
$ docker compose up
$ ./gradlew runShadow
[otel.javaagent 2022-12-15 03:45:35:551+0900] [main] INFO io.opentelemetry.javaagent.tooling.VersionLogger - opentelemetry-javaagent - version: 1.18.0
{"time":"2022-12-14T18:45:42.522Z","message":"Autoreload is disabled because the development mode is off.","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T18:45:45.724Z","message":"Application started in 3.875 seconds.","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T18:45:45.726Z","message":"Application started: io.ktor.server.application.Application@44e3f3e5","logger_name":"Application","thread_name":"main","severity":"INFO"}
{"time":"2022-12-14T18:45:47.223Z","message":"Responding at http://0.0.0.0:8080","logger_name":"Application","thread_name":"DefaultDispatcher-worker-2","severity":"INFO"}
$ curl http://localhost:8080/sample
2022-12-15T04:05:28.119532














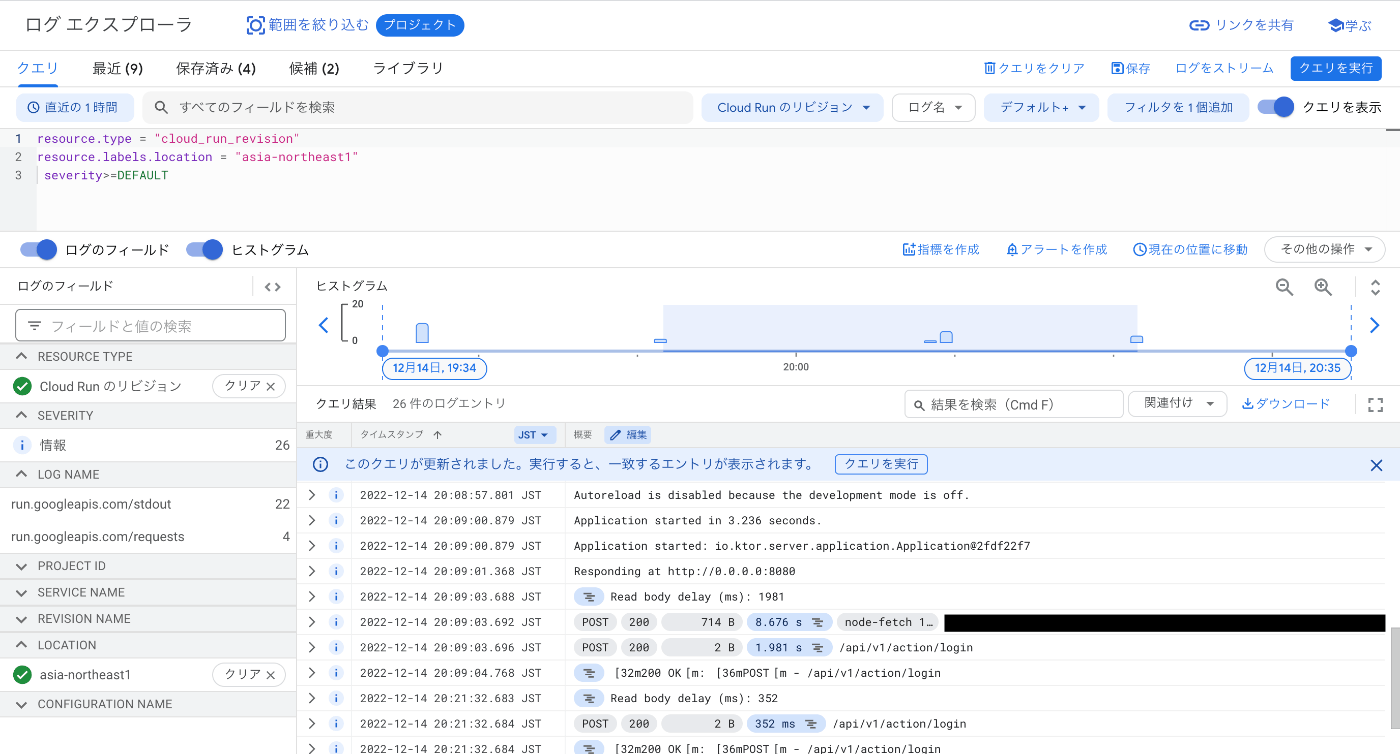
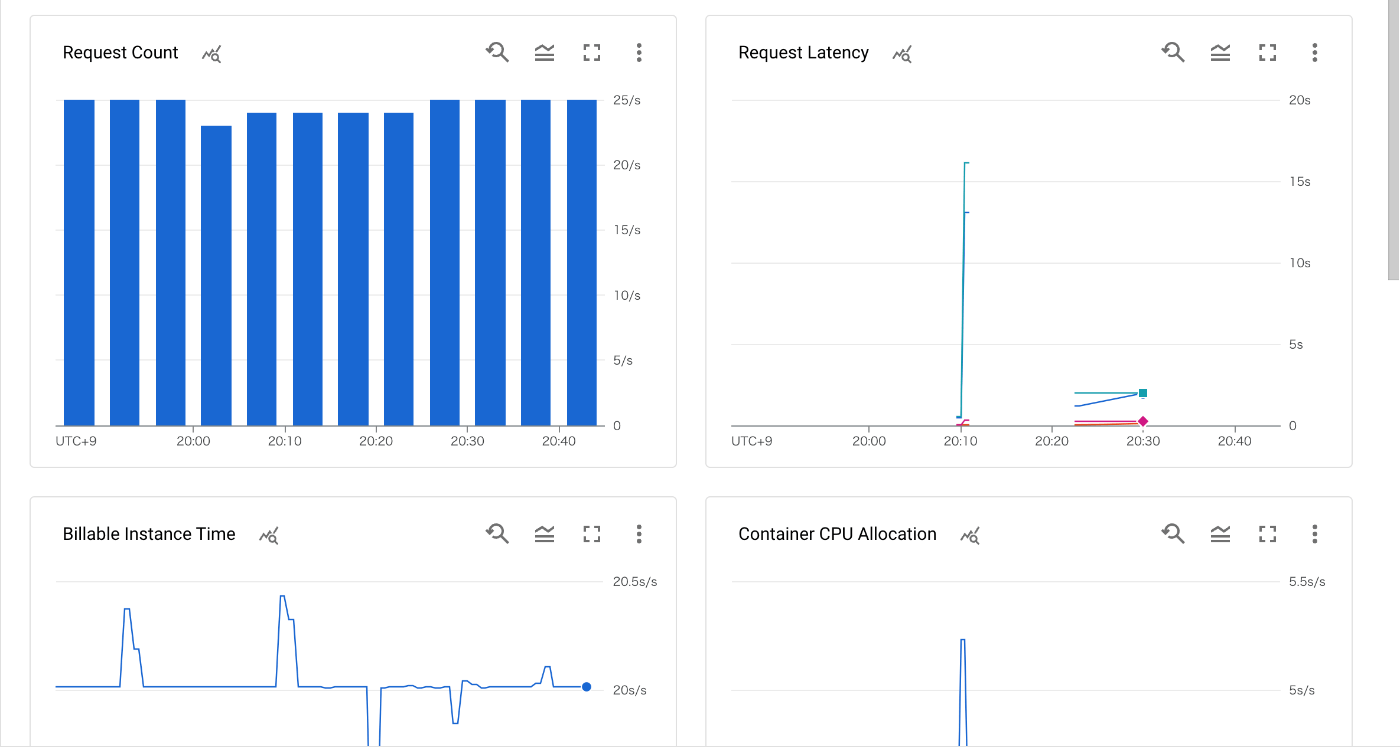
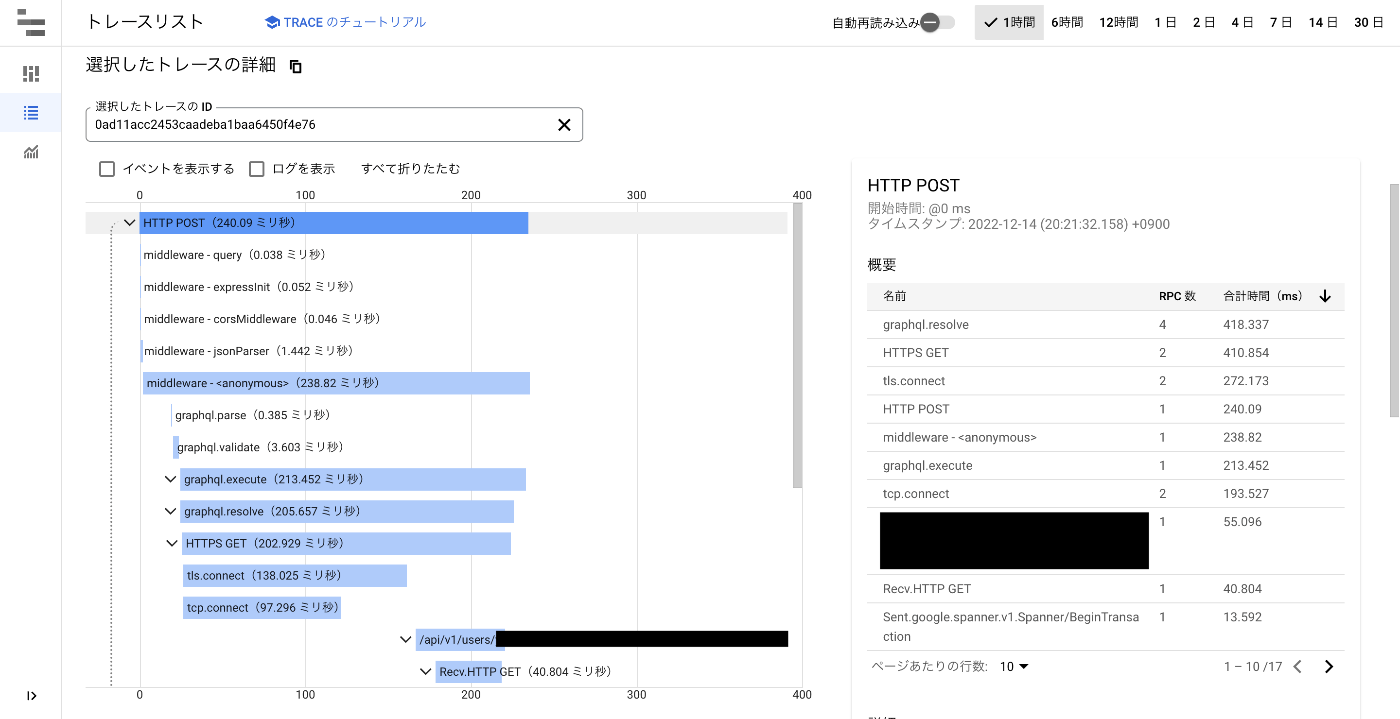
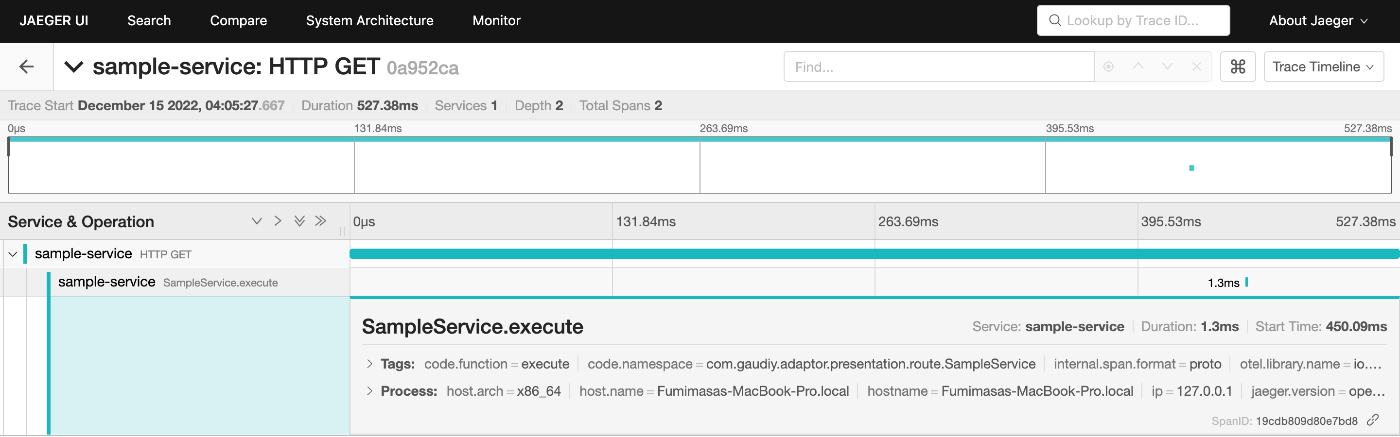
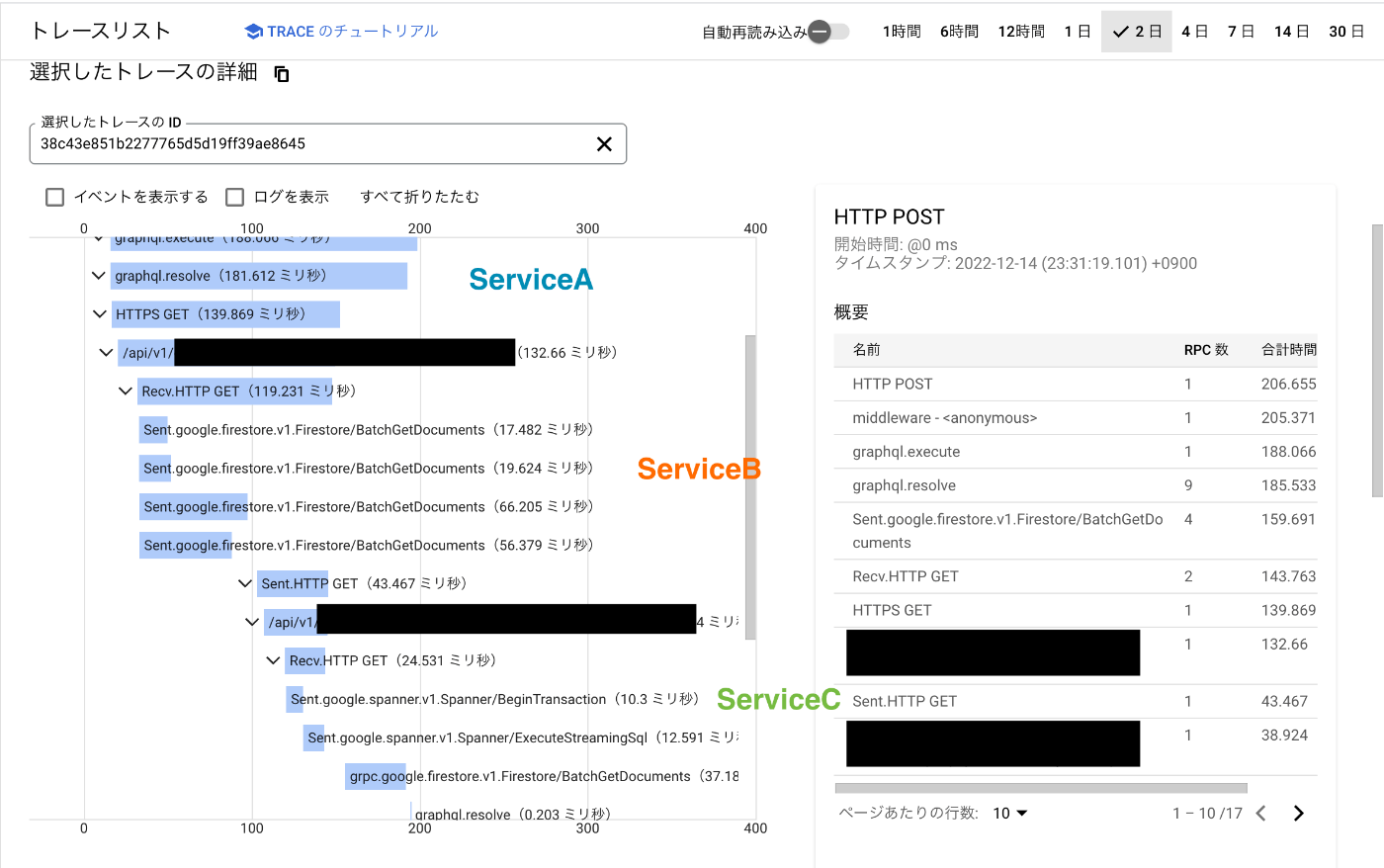
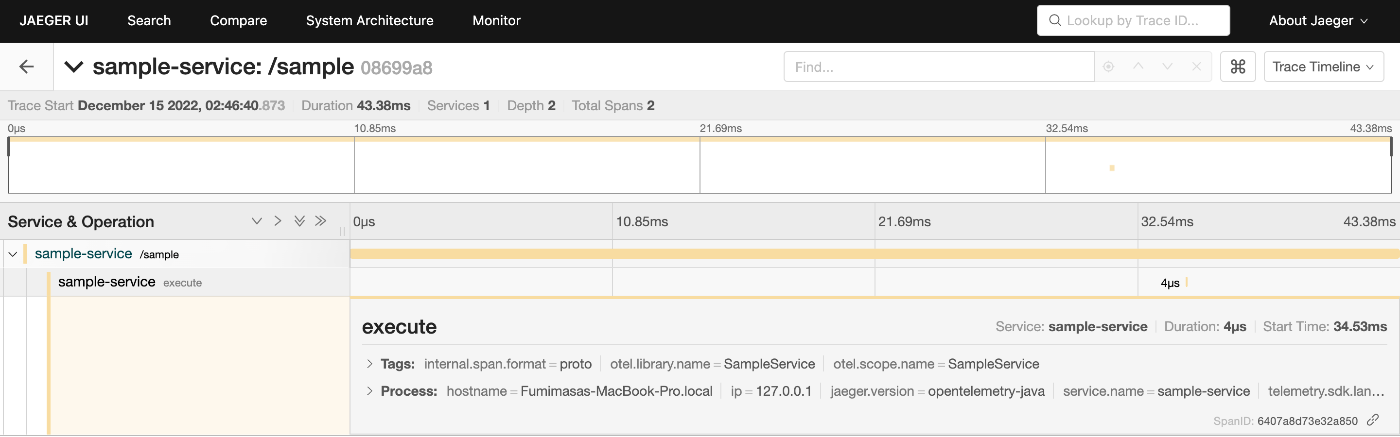 今回はjaegerで確認しましたが、いい感じに記録されてます。
今回はjaegerで確認しましたが、いい感じに記録されてます。