
この記事は、Gaudiyが実施している「Gaudiy Advent Calendar 2022」の20日目の記事です。
はじめまして、Web3スタートアップのGaudiyでエンジニアをしているsato(@yusukesatoo06)です。
GaudiyではGoでのBE開発をメインで担当しており、前職ではNode.jsでのBE開発やFlutterでのモバイルアプリ開発を行っていました!
今回は、Gaudiyのインフラ環境でOpenTelemetry Collector導入のPoCを行ったので、その調査経過を書こうと思います(残念ながらまだ導入には至っていません…)
OpenTelemetry Collectorの記事はあまりないと思うので、導入を考えている方の手助けになれば幸いです🙇
- 1. Gaudiyのアーキテクチャが抱える課題
- 2. 解決策としてのObservability
- 3. OpenTelemetryとは
- 4. OpenTelemetry Collectorとは
- 5. OpenTelemetry Collectorを設定してみる
- 6. 実際に動かしてみる
- 7. 今後やっていきたいこと
- 8. さいごに
1. Gaudiyのアーキテクチャが抱える課題
さて、本題に入る前にGaudiyのアーキテクチャをご紹介します。

このように、BEに関してはGCP Cloud Runベースのマイクロサービス構成となっています。
そのため、マイクロサービスが抱える一般的な課題を、Gaudiyも漏れなく抱えていました。具体的には以下のような課題がありました。(マイクロサービスを扱ってる組織ならおそらく一度は悩むはず…)
- マイクロサービスに分散したログをリクエスト単位で追うのが難しい
- エラーが起きた際にどこのサービスが原因でエラーが起きたかわかりずらい
- レスポンス遅延が起きた際に、どのサービスがボトルネックなのか把握しづらい etc.
その解決に向けた活動の一環が、今回のCollector導入の背景になっています。
2. 解決策としてのObservability
そして、このなかで話題に上がったのがObservability(オブザーバビリティ)です。
オブサーバビリティとは、システムを監視するのではなく「システムの内部で何が起きているのかを説明できる状態を作ること」を指し、クラウドベースのシステムやマイクロサービスを運用するにあたって注目が集まってる領域です。
(参考文献:https://pages.awscloud.com/rs/112-TZM-766/images/20221027_23th_ISV_DiveDeepSeminar_Observability.pdf)
このオブザーバビリティは、以下の3本柱で構成されています。
- メトリクス
- 特定期間のデータの集計値 (何が起きたか)
- トレース
- リクエスト、トランザクションの経過観察 (どこで起きたか)
- ログ
- 特定地点の記録を示す (なぜ起きたか)
これを実現する方法はいくつかありますが、GaudiyではOpenTelemetryというプロジェクトのライブラリを利用することに決定しました。
3. OpenTelemetryとは
OpenTelemetryとは、Cloud Native Computing Foundation(CNCF)でKubernetesに次いで2番目に活発なプロジェクトです。
以下がCNCF内のプロジェクト毎のvelocityなのですが、OpenTelemetryが活発に開発されているのがわかると思います。
https://github.com/cncf/velocity

OpenTelemetryを簡単に説明すると、メトリクス、ログ、トレーシングを包括的に扱うためのプラットフォームで、様々な言語に対応したOSSのライブラリが用意されています。
また元々存在していたOpenMetricsとOpenCensusというプロジェクトが統合されたプロジェクトでもあります。
このOpenTelemetryの使い方については、andoさん(@Andoobomber)が24日目の記事で紹介してくれます。
4. OpenTelemetry Collectorとは
4-1. 概要
OpenTelemetryのライブラリは言語毎に用意されており、すごく便利に扱える一方で、プロジェクトの開発者は言語毎にライブラリの実装が必要となります。そのため、メトリクスを送る先のバックエンドサービス x プログラミング言語の数だけ対応が必要でした。
またOpenTelemetryを利用する側も、取得データに共通する加工やバックエンドサービスの変更をする際にすべてのアプリケーションに手を加える必要があり、一定のコストがかかってしまいます。
上記課題を解決するのがOpenTelemetry Collectorです。
以下がOpenTelemetry Collectorの概要図となっています。このような形で、一度OpenTelemetry Collectorに情報を集約し、その後Collectorがバックエンドサービスにデータを送る形となっています。
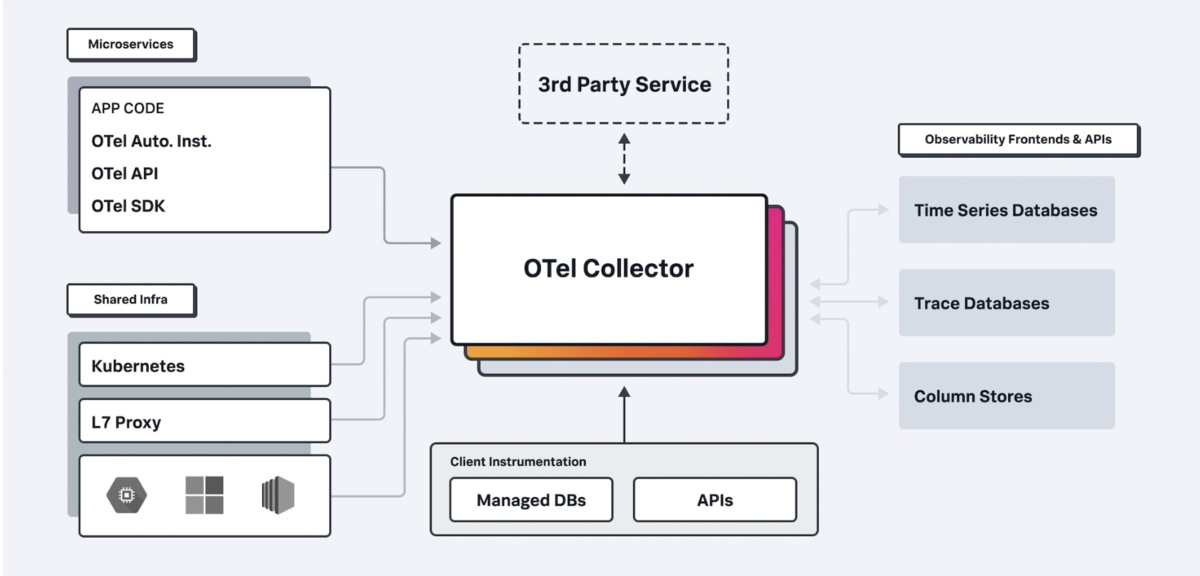
共通の変換処理を行いたい場合や、バックエンドサービスを切り替えたい場合は、Collector側で設定を追加、変更することで共通的に対応することが可能です。
この辺りの設定については次のセクションで詳しく説明します。
4-2. アーキテクチャ
OpenTelemetry Collectorはデータの受信、加工、データの送信を1つのパイプラインとして定義し、処理を行っていきます。またCollectorは1つ以上のパイプラインから構成されます。
アーキテクチャは以下のようになっています。

<Pipeline>
後述するReceiver、Processor、Exporterを組み合わせたもので、メトリクス、トレース、ログそれぞれに対してPipelineを定義することができます。 またそれぞれに対して複数のPipelineを設定することも可能です。
<Receiver>
Receiverとはメトリクス等を受け取るためのパーツです。アプリケーション用にはgRPCとHTTPのインターフェースが用意されており、ライブラリを通じてやり取りすることができます。それ以外にもクラウドサービス用の専用Receiverもあり、クラウドサービス固有の情報も取得することが可能です。
※提供されているReceiver一覧はこちらで確認できます。
<Processor>
Processorは名前の通りReceiverから受け取った値を加工するためのパーツです。メトリクスやログの変換や、トレースデータにラベルを付与したり等いくつかの処理を行うことができます。また、Exporterに流す時の方法だったり流量の制御や、Collectorのメモリ利用量等の制御も可能です。
※提供されているProcessor一覧はこちらで確認できます。
<Exporter>
Exporterはバックエンドサービスにデータを送信するためのパーツです。PrometheusのようなTime Series Databaseや、GCP、DataDogのようなクラウドサービスなど幅広いバックエンドサービスをサポートしています。ここのExporterには複数のバックエンドサービスを設定できるため、一度に複数箇所に書き込むことができます。
またバックエンドサービスを切り替えたい場合は、Exporterの設定を変更するだけでアプリケーションコードに手を加えず変更することができるため、非常に便利です。
※提供されているExporter一覧はこちらで確認できます。
では次のセクションで、実際に動かすための設定を見ていきたいと思います。
5. OpenTelemetry Collectorを設定してみる
5-1. Collectorの入手方法
まずCollectorの入手方法ですが、こちらはいくつか方法があります。
一番簡単な方法はDistributeされているDocker Imageを使う方法です、以下のコマンドでイメージを取得できます。
docker pull otel/opentelemetry-collector:0.67.0
一方で自身でカスタマイズしたCollectorを使いたい場合は、こちらの専用のビルダーを使ってビルドすることが可能です。
5-2. Configuration
まず、今回のPoCで利用したConfigの全体です。(少し記事用に変更してる部分はあります。)
各フィールドの説明は以降のセクションで説明します。
receivers: otlp: protocols: grpc: endpoint: localhost:4317 # Default processors: batch: exporters: logging: verbosity: detailed googlecloud: retry_on_failure: enabled: true project: <プロジェクト名> service: telemetry: logs: level: debug initial_fields: service: poc-instance pipelines: metrics: receivers: [otlp] processors: [batch] exporters: [googlecloud, logging] traces: receivers: [otlp] processors: [batch] exporters: [googlecloud, logging]
<Receivers>
ここではReceiverの設定を行います。アプリケーションからの情報取得であれば、以下のように設定するだけで完了します。
※他のReceiverの設定に関してはこちらをご確認ください。
receivers: otlp: protocols: grpc: endpoint: localhost:4317 # Default
<Processors>
ここではProcessorの設定を行います。今回は複数データをまとめて書き込むためのbatchのみ設定しています。
※他のProcessorの設定に関してはこちらをご確認ください。
processors: batch:
<Exporters>
ここではExporterの設定を行います。今回はPoCということもあり、Collectorの実行環境に出力するための logging と、GCPに出力するための設定を行っています。
※他のExporterの設定に関してはこちらをご確認ください。
exporters: logging: verbosity: detailed googlecloud: retry_on_failure: enabled: true project: <プロジェクト名>
<Service / Pipelines>
Pipelineの設定はserviceフィールドで行います。以下のようにメトリクスやトレース毎に、それぞれどの定義を使うかを選択することでPipelineを組み立てます。
ここの組み合わせを変えることで、メトリクスだけ別のバックエンドサービスに流したり、トレースだけ別のProcessorを挟むことが可能です。
service: pipelines: metrics: receivers: [otlp] processors: [batch] exporters: [googlecloud, logging] traces: receivers: [otlp] processors: [batch] exporters: [googlecloud, logging]
<Debug用>
またserviceフィールドではログを出力する設定もあるため、Debugの際などに使ってみてください。
service: telemetry: logs: level: debug initial_fields: service: poc-instance
<その他>
Collectorの設定の中で同じ種類のフィールドに対して複数の定義を行うこともできます。
例えばotlpのreceiverを複数定義したい場合は、以下のように type[/name] で一意の識別子をつけることで複数定義が可能です。
receivers: otlp: protocols: grpc: http: otlp/2: protocols: grpc: endpoint: 0.0.0.0:55690
また利用する際は、以下のように定義した名前をそのまま使ってあげればOKです。
service: pipelines: traces: receivers: [otlp] processors: [] exporters: [] traces/2: receivers: [otlp/2] processors: [] exporters: []
6. 実際に動かしてみる
「では実際に、上記設定でCollectorを動かしていきましょう」と言いたいところなのですが、GCPへのExporter設定をしている関係で上記設定を手元で動かすことができないため、別の環境と設定を使いたいと思います…
自分でデモ環境を用意しようと思ったのですが、OpenTelemetry内のプロジェクトに素晴らしいデモ用のコードサンプルがあったため、こちらを活用させていただこうと思います。
上記リンクからディレクトリをダウンロードして、docker-compose up -d を実行すると以下の環境が立ち上がります。
※ここにあるZipkin、Jaegerは分散トレーシング用のシステムです

この環境は全ての情報がCollector経由でExportされているため、このディレクトリ内にあるCollectorの設定を色々編集しながらぜひ遊んでみてください。
7. 今後やっていきたいこと
PoCの中でCollectorの有用性は評価できたのですが、Gaudiyのインフラ環境がCloud Runベースのため、どのような構成でCollectorを導入するのがよいかが一番の課題となっています。
まずCollectorをCloud Runでホスティングする案が上がったのですが、Cloud Runの特性上、常時立ち上げておく必要があるCollectorとの相性が悪く断念しました。(ここはもう少し調査の余地があります...)
またインフラ環境を全てGKE上にホストする案や、Collectorだけ別の形でホスティングする案等色々出ています、がCollectorの利用が目的となる案のため保留となりました。
ですので実際の導入方法に関しては、今後継続的に模索していきたいと思っています。
8. さいごに
今回のPoCですが、実はGaudiyの以下の制度を使った取り組みでした!
Gaudiyでは毎週水曜の午後、「EMPOWER-DAY」と称して、チームや会社全体の中長期の成長につなげる様々な取り組みを行っています。直近、この時間の使い方をより効果的にするための変更が行われましたが、基本的に「チームの底上げに時間を使う」という目的は変わらずに取り組んでいます。
このような形でGaudiyには新しい技術の導入を積極的に受け入れてくれる組織文化があるので、おもしろい環境かなと思います。Gaudiyの課題と自分の技術チャレンジをリンクさせて解決してくれる仲間も募集しています!
Gaudiy Advent Calendar 2022の21日目は、同じチームの @hassey_11 さんが担当してくれます!