こんにちは。ファンと共に時代を進める、Web3スタートアップのGaudiyでプロダクトマネージャーをしている@kaa_a_zuです。
開発組織は、ITサービスを提供している企業にとって「エンジン的な存在」であり、プロジェクトや各メンバーの生産性に大きな影響を及ぼします。そんなエンジンは、事業の成長に伴って柔軟に変化させていく必要があると考えています。
Gaudiyでも、これまでに数度、開発組織のアップデートを重ねてきました。今のエンジンは、「仕様策定から開発、リリース、効果測定までをひとつのチームが行い、そのチームメンバー全員が責任を持ってアウトカムの最大化を図ることができる」ものになっています。
そこで今回は、2022年7月に行われた開発組織の体制移行を中心に、これまでの開発組織の変遷から今回の体制に至った背景、体制移行にあたって考慮した点などについて書こうと思います。
事業や人員拡大に伴い開発組織をアップデートする必要性を感じている方や、メンバーが最大限の能力を発揮できていないという課題感のあるエンジニアの方のご参考になれば幸いです。
※少し長いので、現在の開発組織の設計・運用だけ知りたい方は、「3. 開発組織体制の変遷」の終わりまで読み飛ばしてください。
- 1. Gaudiyのプロダクトと技術
- 2. Gaudiyの開発組織
- 3. 開発組織体制の変遷
- 4. 今回の組織体制移行において特に意識したこと
- 5. 組織をワークさせるための工夫
- 6. 現状の課題
- 7. 今後に向けて
1. Gaudiyのプロダクトと技術
まずはじめに、Gaudiyについて簡単にご紹介します。何をやっているかわかりやすく言うと、Web3のコミュニティSaaSをつくっている企業です。
Web3時代のファンプラットフォーム「Gaudiy Fanlink」というプロダクトを、エンタメIP(知的財産コンテンツ)を有する企業に提供して、クライアントの方々と一緒にファンの熱量を最大化させるコミュニティ運営に日々勤しんでいます。
Gaudiyが提供しているのはこのワンプロダクトですが、各IPファンの熱量を最大化させるための手段として NFT(代替不可能なトークン)やDID(分散型ID)といったブロックチェーン技術を利用しています。
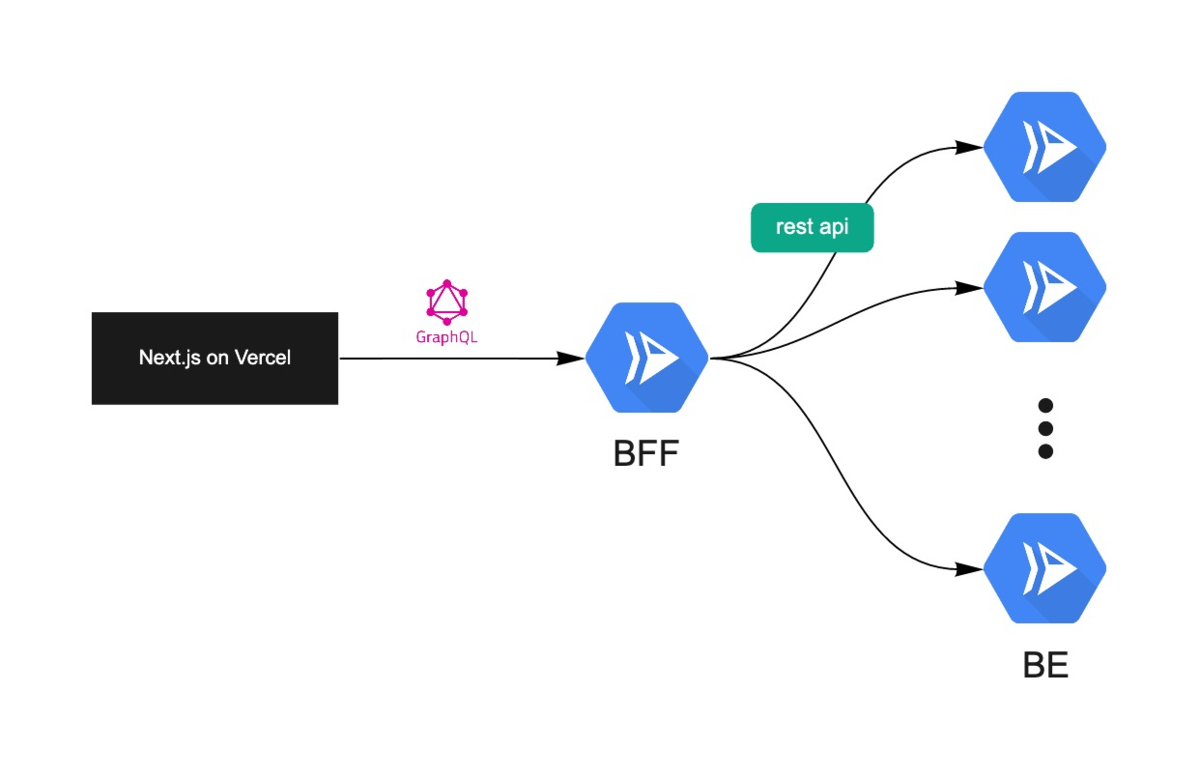
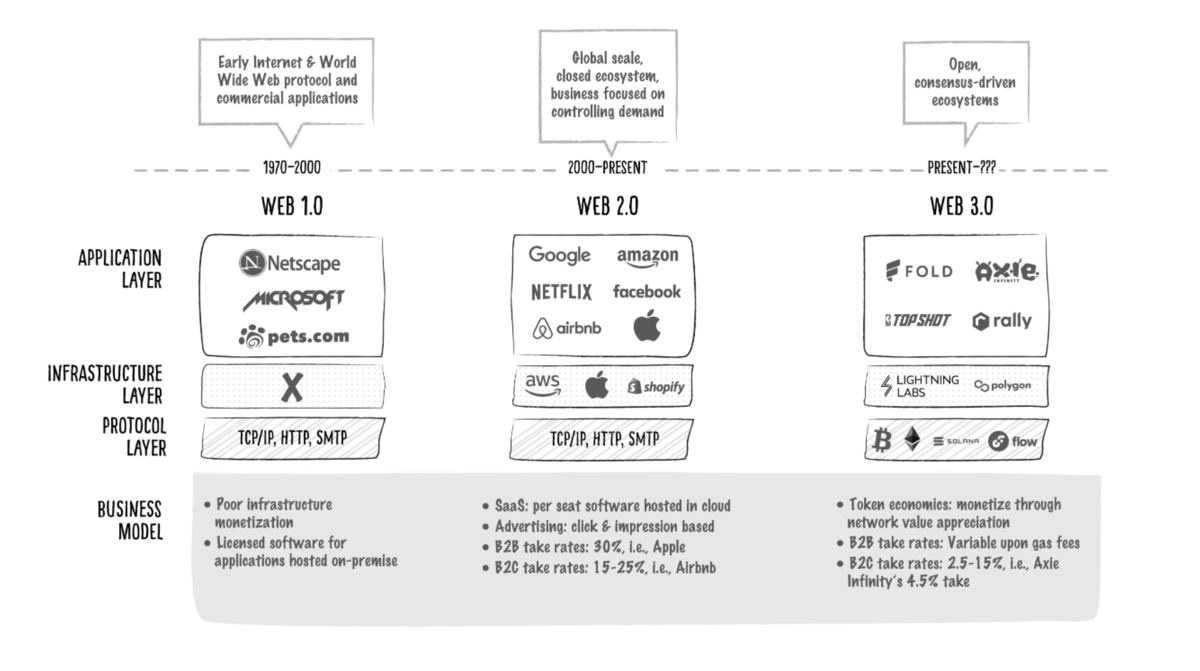
とはいっても、下図のように、いわゆるWeb2の企業が使っている技術と大きな差はあるわけではありません。

よく「ブロックチェーンのことをよく知らなくても大丈夫ですか?」と聞かれますが、Gaudiyでは多くのWeb2企業出身のエンジニアが活躍しています。
2. Gaudiyの開発組織
そんなGaudiyですが、昨今のWeb3やNFTへの注目もあいまって、下図のようにエンジニアメンバーがどんどん増えています。
先日、シリーズBの資金調達が完了したこともあり、今後さらにエンジニア採用を加速させていく予定です。

このような事業フェーズの前進や組織拡大に伴って、開発組織を新たな形に移行する必要がでてきました。
3. 開発組織体制の変遷
ここで一度、創業期からの開発組織の体制について振り返ります。
Gaudiyではこれまでに二度、下図のように組織をアップデートしてきました。それぞれ、どのような背景や意図で組織体制を変えてきたのかについて説明します。
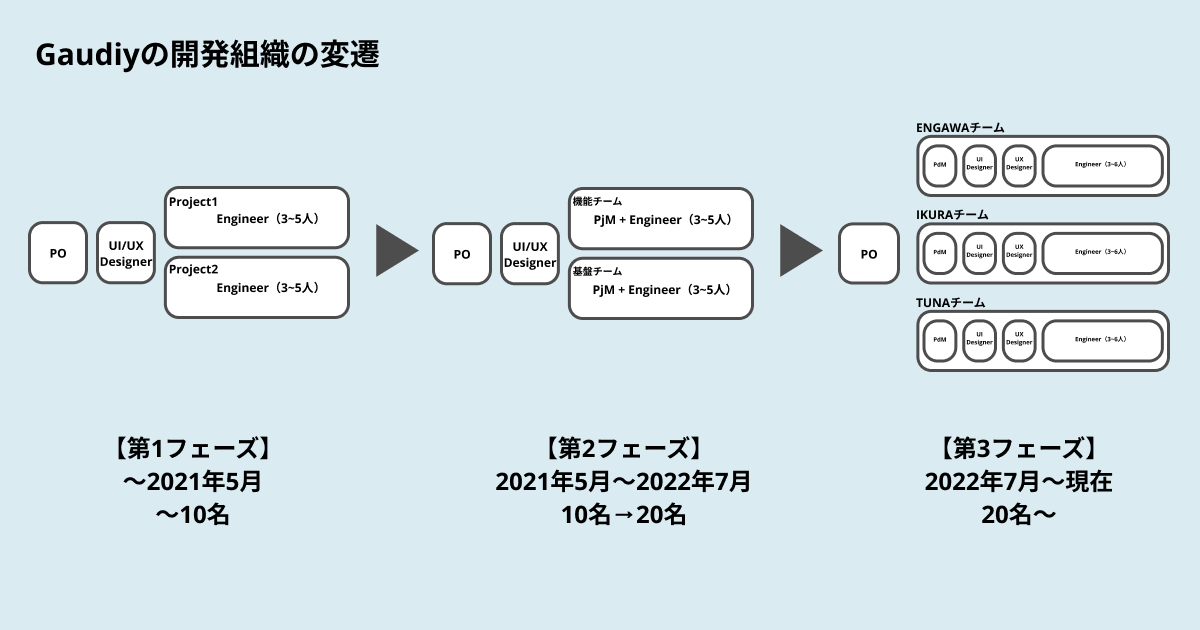
3-1. 【第1フェーズ】創業〜2021年5月

<特徴>
- Engineerは必要最小限のスコープである「プロジェクト」という単位にわかれる
- POとDesignerが仕様をつくり、各プロジェクトでそれらを開発する
この頃は、まさに0→1のフェーズ。創業初期はブロックチェーンの顕在的なニーズが世の中にあまりなく、先行事例も少なかったため、PMFをめざす上で重要だったのは「いかに関係者に価値を理解してもらえるか」でした。
そこでまずは、クライアント企業に深く入り込み、個別の状況に対して理解と共感を深め、エンタメ企業に共通するペインを見つけながら、それを解決するプロダクトをつくる。そのプロセスが必要であり、戦略的に「Sales-Led Growth(セールス主導の成長)」でのプロダクト開発をしていました。
プロダクトが小さくメンバーも少なかったため、開発スタイルとしては、POとメンバーが密にコミュニケーションを取りながら、アウトプットを重視する形です。不確実な課題に対しての突破力が高いメンバーで構成されており、早いスピードで確実にアウトプットを積み上げていました。
この開発体制によって、複数のクライアント企業様と一緒にコミュニティを提供できたことで、プロダクトの大枠をつくることができました。同時に、後に想定される「SaaSとしての急成長に備えた地盤を整えること」が課題となってきました。
3-2. 【第2フェーズ】2021年5月〜2022年7月
その課題に対応するために、2021年5月頃から、「継続的にコミュニティの機能をつくるExperienceチーム」と 「決済システムや他のプラットフォームと連携するためのSDK、IDシステムなどの基盤をつくるPlatformチーム」の2チームに分かれました。

<特徴>
- Engineerは機能をつくるチーム(Frontend Engineer中心)と、基盤をつくるチーム(Backend Engineer中心)にわかれる
- POとDesignerが仕様をつくり、各チームでそれらを開発する
- 各チームの開発スケジュールを管理するProject Managerのポジションが生まれる
この時代も、継続して戦略的なSales-Led Growthでの開発をしていました。セールスのニーズにあわせた開発をしていたため、運用するコミュニティの数も着実に増えていきました。また、増えてきたメンバーをまとめるため、プロジェクトマネージャーのポジションが新設され、個の集合からチーム感が強くなっていきました。
ここで課題となってきたのが、「SaaSとしての汎用性」と「1つ1つの機能の質」です。
Product-Led Growth(プロダクト主導の成長)ではなく、スピードとアウトプットを重視したSales-Led Growthでの開発を戦略的に採用してきたために、すべてのコミュニティに汎用的な最大のアウトカムは出せていない状態でした。
また他にも、以下のような課題が浮き彫りになってきました。
- Designerのリソース不足で、仕様策定者のPOとDesignerの間で機能の細部要件が定まらず、開発に手戻りが生まれる
- メンバーの増加に伴い、コミュニケーションが複雑になり、よりトップダウン開発の色が濃くなってしまった
- なぜその仕様でその機能を作るのかの共通認識をメンバー全員が取れていない
3-3. 【第3フェーズ】2022年7月〜現在
こうした課題に対応するために、個々のチームが仕様策定からユーザーへの提供までを一貫して担い、それらが並存する組織体制に移行しました。これが現在の開発組織体制です。

<特徴>
- 仕様策定からユーザーに体験を届けるまでを一貫して担うため、EngineerはFrontend、Backendという分かれ方はせず、クロスファンクショナルなチーム構成になる。
- POが事業進捗をふまえた開発の優先順位を決定し、PdMを中心にチーム全員で仕様をつくり、それらを開発/提供/効果検証する。
- 特定の開発領域をもたないため、チーム名のつけかたを「寿司ネタ」にする。(社内公募で決めました。)
ひとつのプロダクトに対して、2022年9月時点で開発チームは3つです。現在は、横断的なチームは存在していません。
Gaudiyは、2022年の5月にシリーズBの1st、8月に2ndの調達をしました。次はいよいよシリーズCになります。
次のマイルストーンとして、私たちは「シリーズCでユニコーン企業になる」を本気で目指しており、その目標達成のために今までの開発の仕方を大きく変更する必要が出てきました。
ここからは、どんなことを考えて現在の開発組織を設計したか、そしてどのように組織運営をしているかについてお伝えしていきます。
4. 今回の組織体制移行において特に意識したこと
メンバーが増え、組織が拡大するにつれて、組織体制を変えることにはリスクが生じます。社員数が50人に満たないGaudiyでさえ、私はこの難易度が高いと感じていました。大前提、すべての理想を叶えられる組織体制は存在しないと思っています。
また基本的に、恩恵を享受する時には痛みも伴います。このようなトレードオフの関係になり得る重要な意思決定においては、特に意識しないといけないことが2つあると考えています。
1つ目に、絶対に譲れないコアな考え方を決めること、2つ目に関わるメンバーの納得感を得ることです。それぞれ具体的にお伝えします。
4-1. 譲れないコアな考え方を決める
今回の開発組織の体制移行に際して、以下3つをコアな考え方として定めました。
- アウトカムに責任が持てるチームであること
- すぐに新たなポジションは作らないこと
- 文化が継承されること
これらについて、順番に説明します。
4-1-1. アウトカムに責任が持てるチームであること
以前までは、アウトカムよりもアウトプットを重視した開発をしていました。ここからのフェーズでは多少のスピードを犠牲にしてでも、アウトカムを重視した開発をしていく必要があります。
ユーザーに対するアウトカムを最大化するためには、ユーザーが本当にやりたいことを探り、提供し、改善していくことが必要だと考えています。つまり、Whyを意識しながら仕様策定や微小な軌道修正を繰り返すことのできる開発組織の体制が必要です。
そのためには、POが細部まで仕様策定したものをチームが開発するといった社内受託感をなくし、開発チームが能動的にそれらについて考えることができ、アジリティ高く、タスク完結性を持って遂行可能な状況をつくる必要がありました。
- アジリティ…企業のビジョンと一致している方向に、各々が意思決定ができている度合い
- タスク完結性…各々が作業工程の一部ではなく最初から最後までに取り組めること
この状況を作るために、変更したのは3つです。
- 今までのPjM(Project Manager)というポジションをPdM(Product Manager)に変え、チーム内での最終的な意思決定の責任者に。
- 各チームが開発するプロダクトバックログを決める会議体を新設。
- 仕様策定からリリースまでを1つのチームだけで一貫して行えるクロスファンクショナルなメンバー構成に変更。
図示すると下図のようになります。

当然かもしれませんが、タスク完結性がなければその決定に対してチームや個人が感じる責任は小さくなり、考えるプロセスにおいて他責感を生んでしまいます。
新しい体制は、チームがタスク完結性を持つ構造にしているため、否が応でも決定に対しての責任を持たなくてはいけない構造です。結果的に、アウトカムについてチームや個人がより意識をするため、ユーザーにとってより良いものが提供できるという状況が生まれています。
4-1-2. すぐに新たなポジションは作らないこと
組織体制を変えるタイミングでやってしまいがちなことのひとつが、新たなポジションを作ることだと思っています。
特定の課題を解決することの単純解が、ポジションの新設です。今回の議論でも「QAエンジニア」「Engineering Manager」「スクラムマスター」などの新たなポジションをつくりたいという声が上がりました。
結論、今回の体制移行に伴って新たなポジションをつくることはしませんでした。なぜかというと、ポジションをつくることは簡単でも、減らすことはとても難しいと考えているからです。
一度ポジションをつくってしまうと、そこにアサインされた人が「今まで持っていた裁量を失うこと」を恐れたり、アサインから外れることがモチベーションを落とす要因にもなり得ます。そのため、ポジションの新設による課題解決は、安易に選択すべきではないという結論にいたりました。
この辺りの「裁量とモチベーションの関係」については、米・ハーバード大学で心理学の教授をされている ダニエル・ギルバート氏 の著書で分かりやすく説明されています。
改めてになりますが、ポジションをつくりたいという議論が出てきた時には、第一に仕組みで解決することができないかを模索し、試行錯誤をした後で本当に必要だったらポジションを新しく設ける、という流れが大事だと思っています。
4-1-3. 文化が継承されること
スタートアップの成長過程でよく言われているのが「30人の壁」「50人の壁」「100人の壁」です。
これらは組織規模がおおよそその人数になった時に、組織に対する満足度が低下し、結果として離職率が高まることを指します。これらの障壁の原因は、「文化の希薄化」と「1人当たりが持つ影響力の低下」だと言われています。
創業まもない少人数の時はプロダクトも小さく、ステークホルダーも少ないため、全員で意思決定をしてつくることに必死になります。その後、企業が有名になり組織が拡大していくと、途中で入社してきた経験豊富な優秀な人中心の構造になり古参メンバーがモヤを感じてしまったり、今まで知れていたことが知れなくなったり、以前と比べて組織に対する影響力が小さくなってしまいます。
Gaudiyの場合、まだエンジニアメンバーが20人未満だということもあり、そのまま進めることも可能でした。しかしながら、拡大スピードを考えると、早めに次の一手を打たないといけないような状況でした。
そのために各チームに企業文化を持っていて浸透させることができる古参メンバーが在籍する構成にしたり、全ての情報をアクセス可能にしたり、チーム間でのコミュニケーションが取れる(極論、取らなければいけない)開発の流れにしています。
このあたりは、開発組織だけでなく、GaudiyのバリューのひとつでもあるDAO(Decentralized Autonomous Organization:自律分散型組織)がベースになっています。以下の記事で詳しく説明しているので、よければご覧ください。
4-2. 関わるメンバーの納得感を得る
組織体制の変更は、今まで慣れ親しんだ開発手法や今後のキャリアにも影響が出ます。そして、メンバーはロボットではなく、感情をもつ "人" であり、その誰しもがコンフォートゾーン(居心地の良い環境)を探してしまうものです。
その前提のもと、今回の移行に際しては、全開発メンバーにヒアリングをして意見を聞き、できる限りのwillを反映させました。
組織体制の変更について考えている時は、どうしても視点が組織に向いてしまいがちですが、その視点だけではロマン(表層)的にしか描くことができません。チームや個人といった現場(本質)的視点を入れることで、より現実的で納得感が得られる体制を描けるのだなと学びました。
実際に、全員と数回の1on1を行うことはかなり大変でした。ただ、これから強い組織が成長するためには、今までのGaudiyを築いてきたメンバーがとにかく大切です。そのメンバーが持つモヤをなくし、組織基盤となる文化や考え方を新たなメンバーに浸透させることは、1on1を行う大変さに比べて何十、何百倍も大事だと思っていました。
それらを経て、最終的には社内AMA(Ask Me Anything)も開き、納得感を得て体制移行を完了できたのではないかと思っています。
5. 組織をワークさせるための工夫
すでに3ヶ月弱、この開発組織体制で動いていますが、実際にうまくワークしているのか?について最後に触れておきます。
結論、課題は山積みですが、今のところうまくワークしていると感じています。今までは開発組織の体制づくりに着目して説明をしてきましたが、ここからはこの組織体制における運用の工夫についてご紹介します。
5-1. 定期的に組織課題を改善するMTGを開く
組織課題は業務を重ねるにつれて顕在化し、日々更新されていきます。そこで、約2週間に1回の頻度で組織課題を改善をするミーティングを開いています。
この会議体の責任者はPdMですが、実際にそれぞれの解決に責任を持って旗を振る人は、その課題を挙げた人になることが多いです。今後も継続的にこのミーティングを行っていく必要があるなと感じています。

5-2. いつどこのチームが何に着手するのかを可視化する
ワンプロダクトを複数チームで開発する体制なので、他のチームが取り組んでいる開発領域を知り、お互いにコミュニケーションを取りながら開発をしていく必要があります。
そこで、他のチームがやっていること/今後やることをタイムライン形式で表示し、簡単に知ることができる状態にしています。

また下図のように、弊社のプロダクトバックログには、今後開発をしたい機能(正確にはアウトカムベースのストーリー)があります。
これらをカンバン形式でも見ることができるため、開発メンバーが将来的にどういった機能が載るのかをイメージしながら、現在の開発ができるような状態にしています。(= 拡張性の考慮)

5-3. 通常業務禁止DAYで横断的にDX改善を行う
繰り返しになりますが、Gaudiyでは現在、横断的なチームは存在しません。
一般的に、横断的なチームがやることとしては、技術選定基準や開発方針の決定、難易度が高い開発、横断的に行う必要があるメトリクス計測の開発などがあると思います。
横断的なチームには、上述したようなことにフォーカスして着手できるメリットがある一方で、生じ得るデメリットとしては、組織として階層構造になってしまったり、横断的なチームが社内受託的な組織になってしまうなどが考えられます。
今のフェーズにおいては、できるだけ全員がオーナーシップを持ってレバレッジの効くDX改善に取り組むことが大事だと思っています。これを実現可能にしているのが、毎週水曜日にある「EMPOWER-DAY」です。
この日は午前が休み、午後は通常業務を原則してはいけない決まりになっています。この曜日を使って、チームに関係ない開発メンバーとのDX向上に取り組んでいます。具体的には以下のような取り組みが行われています。

なお、事業フェーズが進み組織が拡大する中で、横断的なチームが今後誕生する可能性はあります。Empower-Dayが誕生した背景や具体的な内容については、以下の記事で詳しく説明しています。
6. 現状の課題
上述したように、様々な仕組み化によって改善はしているものの、まだまだ多くの課題があります。
ここでは、今後解決していきたい課題についてお伝えします。
6-1. 意思決定責任の所在が明確化されないこと
開発組織が階層構造になっていないことや、特定のことを行う横断的な組織がないことにはデメリットがあります。
そのひとつが、全員がオーナーシップを持っているが故に、開発時の意思決定スピードが落ちることです。これについては、取り組みごとに最終意思決定者(≒責任者)を明確にするような形で推進しており、徐々に解消している最中です。
6-2. 開発時のコミュニケーション過多、コンフリクトが生じる
現在のプロダクトは小さく、機能もそこまで多くないため、チームごとの担当領域を定めていません。つまり、ワンプロダクトにおける体験ごとにタスク完結性を持って開発する運用になっています。
この運用(体制)では、他のチームが取り組んでいる開発領域を知り、お互いにコミュニケーションを取る必要がありますが、これには一定のコストがかかります。そして、これらの課題はチームが増えるごとにさらに大きくなっていくことが予想されます。
このコミュニケーションコストが許容できなくなるタイミングでは、逆コンウェイの法則に従って、担当する領域を明確化した機能単位のチームに移行することが望ましいのかなと現時点では考えています。
7. 今後に向けて
やはり、プロダクトと組織は切っても切り離せない関係にあると思っています。つまり、強い組織をつくることができれば、おのずと良いプロダクトをつくれる可能性が高くなるはずだと考えています。
ここからGaudiyは、さらに大きくなっていきます。2022年時点で20人ほどの開発組織も、2023年には50人、2024には100人に大きくしていき、グローバルに向けた挑戦をしていきます。
すごくおもしろいフェーズだと思うので、少しでも興味持ってくださった方はぜひカジュアルにお話ししたいです。
エンジニア向けの採用ページもできたので、貼っておきます!