こんにちは。エンタメ領域のDXを推進するブロックチェーンスタートアップ、Gaudiyでエンジニアをしている高島(@takashima_katsu)です。
Gaudiyでは現在、BFFレイヤとしてGraphQLサーバを利用しています。導入してから1年以上が経ちますが、スキーマ駆動開発はDXの向上につながっていると実感しています。(以下のブログが詳しいです。)
今回は、GraphQLの利点を活かしたエラーハンドリングの方法について、Gaudiyでの実践をもとに書いてみたいと思います。エラーハンドリングの実装について課題感のある人や、現在GraphQL Errorsを使っている人に、ぜひ読んでいただけると嬉しいです。
1. エラーハンドリングとGraphQL
エラーハンドリングとは、プログラム実行時にエラーが生じた際に、すぐにその実行を終了させず、あらかじめ用意しておいた処理を行うことです。これをすることで、意図しない構造のデータが保存されたり、異常終了してしまう事態を防ぎます。
Gaudiyでは、GraphQLでのエラーハンドリングを行っており、そのベストプラクティスを探ってきました。
GraphQLの特徴は、データをモデル化し、スキーマとして定義することです。これによって、APIドキュメントなどを別途作成せずとも、クライアントがイントロスペクションを通じてスキーマの詳細を知ることができ、必要な情報を要求することができる、というメリットがあります。
GraphQLエラーハンドリングにおける一般的な手法としては、以下の errors エントリーにエラーの詳細を含める、GraphQL Errorsがあると思います。
{ "errors": [ { "message": "Name for character with ID 1002 could not be fetched.", "locations": [{ "line": 6, "column": 7 }], "path": ["hero", "heroFriends", 1, "name"], "extensions": { "code": "CAN_NOT_FETCH_BY_ID", "timestamp": "Fri Feb 9 14:33:09 UTC 2018" } } ] }
これは GraphQL SpecのErrorsセクション から持ってきたものです。このエラー表現を、後述するエラー表現と区別するために、便宜上「トップレベルエラー」と呼びたいと思います。
トップレベルエラーは、GraphQL Specでも説明されていたり、GraphQLサーバの実装でよく使われる Apollo Server のドキュメントでも紹介されているので、よく利用されている表現だと思います。
しかし、ここで考えていただきたいのですが、これはGraphQLの利点を活かすことができているのでしょうか?
今回はその課題提起と、解決策としての実装方法について紹介したいと思います。
2. GraphQL Errorsにおける課題
GraphQLの利点は、先述の通り、スキーマとして定義することで、クライアントがイントロスペクションを通じてスキーマの詳細を把握できる点にあります。
ですが、トップレベルエラーには、このスキーマがありません。そのため、クライアント側がどういったエラーがあるかを知ることができなかったり、型の自動生成もできなかったりして、別途、ドキュメントの作成やコミュニケーションコストが発生してしまいます。
また実際に運用していく中で、エラーの追加や変更に気がつかず、フロントで適切なエラーフィードバックを出せなくなってしまったり、そもそもエラーによって細かくフィーバックを出すことが億劫になってしまい、抽象度の高いエラーフィードバックを出してしまうこともありました。
結果として、Gaudiyが大事にしている『Fandom』ではない体験の提供につながってしまったり、DXも悪くなってきていると感じていました。
また、 extensions エントリーなどでエラーを拡張したりと便利なことも可能ですが、これもスキーマ外で定義することになるため、同じように別途ドキュメントの作成が必要でした。
3. GraphQLエラーハンドリングの実践
こうした課題に対して、エラーもデータと同じようにモデル化し、スキーマとして定義する方法を取り入れていきました。このスキーマでのエラー表現を、トップレベルエラーと区別するために、便宜上「スキーマエラー」と呼びます。
ここからは、Gaudiyでは実際、どのようにスキーマエラーを実装しているのかについて説明していきます。
3-1. エラーの分類
まずは、エラーを分類します。エラーの種類によっては、今まで通りトップレベルエラーを使った方が良いケースもあり、Gaudiyでも多くのエラーではトップレベルエラーを利用しています。
具体的には、「例外エラー」と「ドメインエラー」の2つに分類しており、前者ではトップレベルエラーを、後者ではスキーマエラーを使用しています。この分類は、GraphQLの作者の1人であるLee Byronも、いくつかのissuesで触れています。
GraphQL errors encode exceptional scenarios - like a service being down or some other internal failure. Errors which are part of the API domain should be captured within that domain.
https://github.com/graphql/graphql-spec/issues/391#issuecomment-385553207
The general philosophy at play is that Errors are considered exceptional. Your user data should never be represented as an Error. If your users can do something that needs to provide negative guidance, then you should represent that kind of information in GraphQL as Data not as an Error. Errors should always represent either developer errors or exceptional circumstances (e.g. the database was offline).
https://github.com/graphql/graphql-spec/issues/117#issuecomment-170180628
「サーバが落ちている」などのシステム系のエラーは「例外エラー」に、「認証情報がない」などのドメインに関するエラーは「ドメインエラー」に分類するようにします。
3-2.ドメインエキスパートへのヒアリング
スキーマエラーの対象となる「ドメインエラー」は、その名の通り、ドメイン知識として扱います。
そのため、どのようなエラーが考え得るかについて、ドメインエキスパートへのヒアリングを通じて、チームで共有することが大事です。 Gaudiyの場合は、実例マッピングや受け入れ基準設定のときに、どういった失敗ケースがあるのかを洗い出しています。
その後、 どのようなフィードバックを出すのがユーザー体験として良さそうかを、CSやデザイナーと議論しながら進めています。
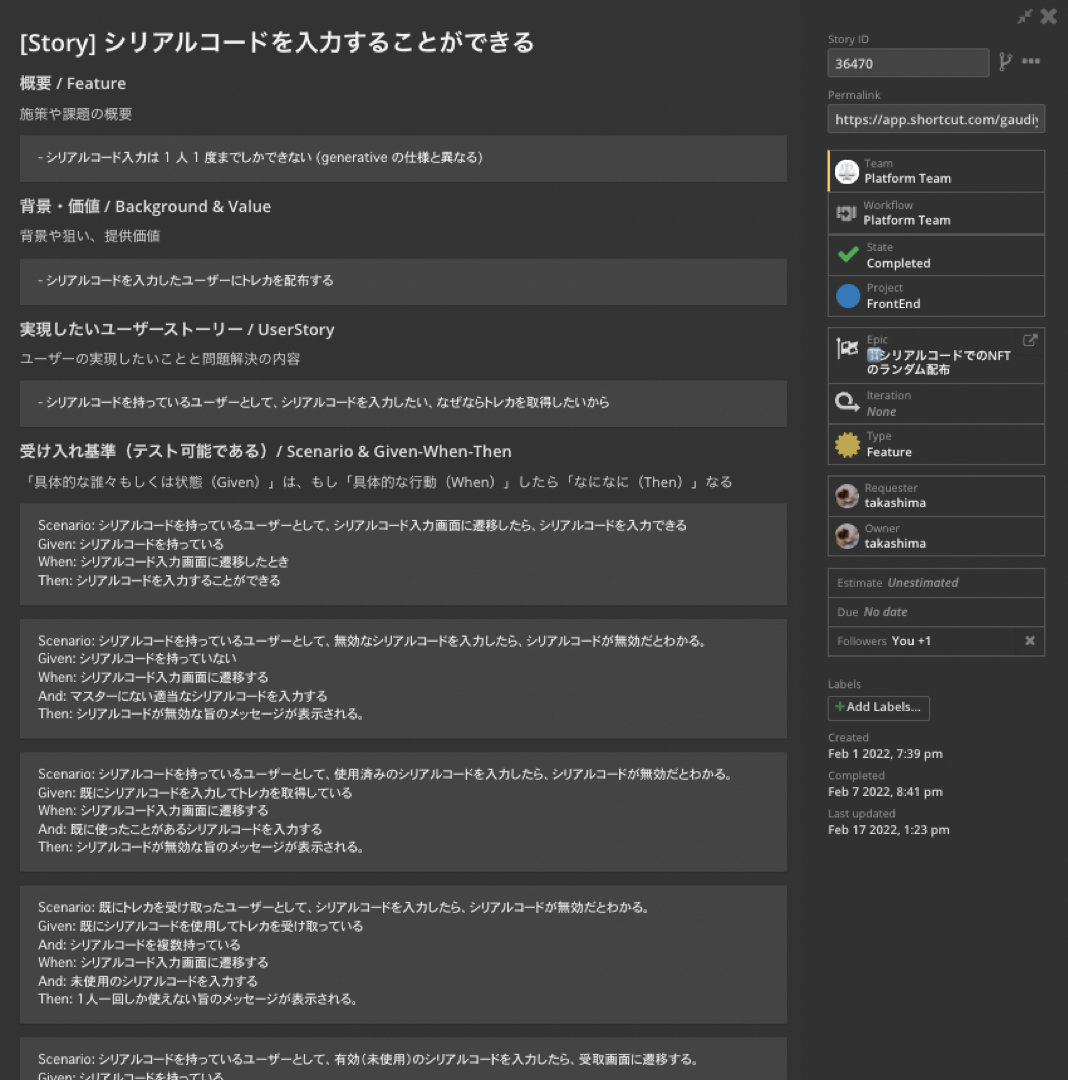
これは、最近「シリアルコードを入力してNFTを受け取れる」という機能を実装した際の、実際のチケットです。実例マッピングをして、受け入れ基準の設定まで行いました。(Gaudiyではこのように、ユーザーストーリーベースでチケットに書くようにしています。)
どういった失敗ケースがあるのかをチケットの受け入れ基準に書いていますが、それをそのままスキーマで定義します。
""" エラー: 該当しないシリアルコードの場合 """ type CheckSerialCodeNotApplicable {} """ エラー: 既に使用されているシリアルコードの場合 """ type CheckSerialCodeAlreadyUsed {} """ エラー: シリアルコードの入力回数が上限を超えている場合 """ type CheckSerialCodeUsageLimitExceeded {}
3-3. Union を使った Result 型の作成
先ほど定義したスキーマをもとに、Result型を作成し、オペレーションタイプの返り値として返す方法を採用しています。
こちらの方法は 『200 OK! Error Handling in GraphQL』 で詳しく説明されているので詳細は省きますが、以下のように定義することができます。
type Mutation { """ シリアルコードの入力チェック """ checkSerialCode(serialCode: String!): CheckSerialCodeResult! } union CheckSerialCodeResult = CheckSerialCodeSuccess | CheckSerialCodeNotApplicable | CheckSerialCodeAlreadyUsed | CheckSerialCodeUsageLimitExceeded """ 成功 """ type CheckSerialCodeSuccess {} """ エラー: 該当しないシリアルコードの場合 """ type CheckSerialCodeNotApplicable {} """ エラー: 既に使用されているシリアルコードの場合 """ type CheckSerialCodeAlreadyUsed {} """ エラー: シリアルコードの入力回数が上限を超えている場合 """ type CheckSerialCodeUsageLimitExceeded {}
この方法は、複数のエラーを同時に返せないなどの制約はありますが、シンプルな実装になっています。
また、複数のエラーを同時に返したい場合などは、『A Guide to GraphQL Errors』 の Error Union List の方法が参考になると思います。
mutation Mutation($serialCode: String!) { checkSerialCode(serialCode: $serialCode) { ... on CheckSerialCodeSuccess { } ... on CheckSerialCodeNotApplicable { } ... on CheckSerialCodeAlreadyUsed { } ... on CheckSerialCodeUsageLimitExceeded { } } }
このようにスキーマエラーを使うことで、フロントはスキーマの詳細を知ることができ、 __typename の分岐でエラーフィードバックのハンドリングを行うことができるようになります。
4. まとめ
この記事では、Gaudiyで実践している、GraphQLのエラーハンドリングの方法についてご紹介しました。
エラーを「例外エラー」と「ドメインエラー」に分類し、ドメインエラーをスキーマとして定義することで、 DXの良いハンドリングを行うことができます。ドメインエラーはドメイン知識とイコールなので、ドメインエキスパートへのヒアリングを通じて洗い出していくことが大事です。
GraphQLの特性を活かしたエラーハンドリングの仕方として、ご参考になれば嬉しいです。この辺り興味ある方いれば、ぜひお話ししましょう!
https://meety.net/matches/YEieGYUZDYhr
Gaudiyの技術スタックやその選定思想については、こちらの記事をご参考ください。